Liberate Your Mainframe Data with Change Data Capture (CDC) and Event Streaming
Discover how your organization, working with Converge Technology Solutions and Confluent, can unleash your mainframe data using Confluent Cloud, Connect, and data-driven transformation to power your modern applications.


Organizations around the world have come to rely on the mainframe for reliable, high performance compute and storage for their critical systems. As a result, they are the bastion of key data for mature organizations, and often are the system of record and processing for core capabilities.



Mainframes are set to remain a cornerstone in enterprise infrastructure for the foreseeable future, which requires mainframe data be made readily available to other solutions, particularly in the cloud. This need arises as business systems and customer experiences have evolved to require modernized workloads, and traditional IT departments find it challenging to integrate directly with mainframes due to inefficiencies, high costs, security risks, and poor performance.
To overcome these challenges, it is key that the mainframe data is efficiently and reliably accessible across various systems and to be kept up to date as much as possible. By using change data capture and data-driven event stream transformation, the data can be pushed to any number of systems though Confluent and made available so that cloud-based systems and other platforms can enjoy high-performance, low-cost access to the critical mainframe data.
Liberate Your Mainframe Data with CDC and Event Streaming
Synchronize your critical mainframe data to where you are interacting with your customers and workloads are moving, without adding undue stress to your mainframe. Key benefits include:
Reduced resource utilization on the mainframe
Data moved to modern, managed databases on cloud
Data-driven data mappings simplify and accelerate the development of mappings between systems
A modular and flexible architecture that is ready for future integrations
Build with Confluent
This use case leverages the following building blocks in Confluent Cloud:
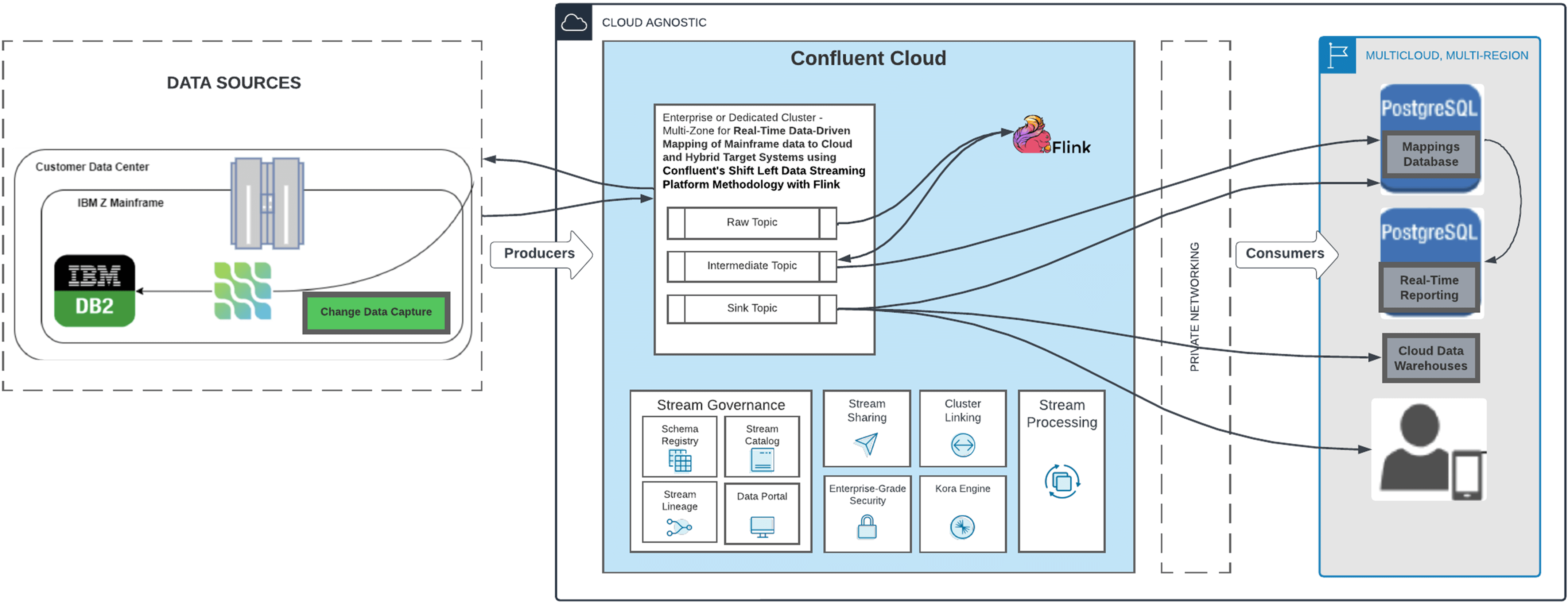
Reference Architecture
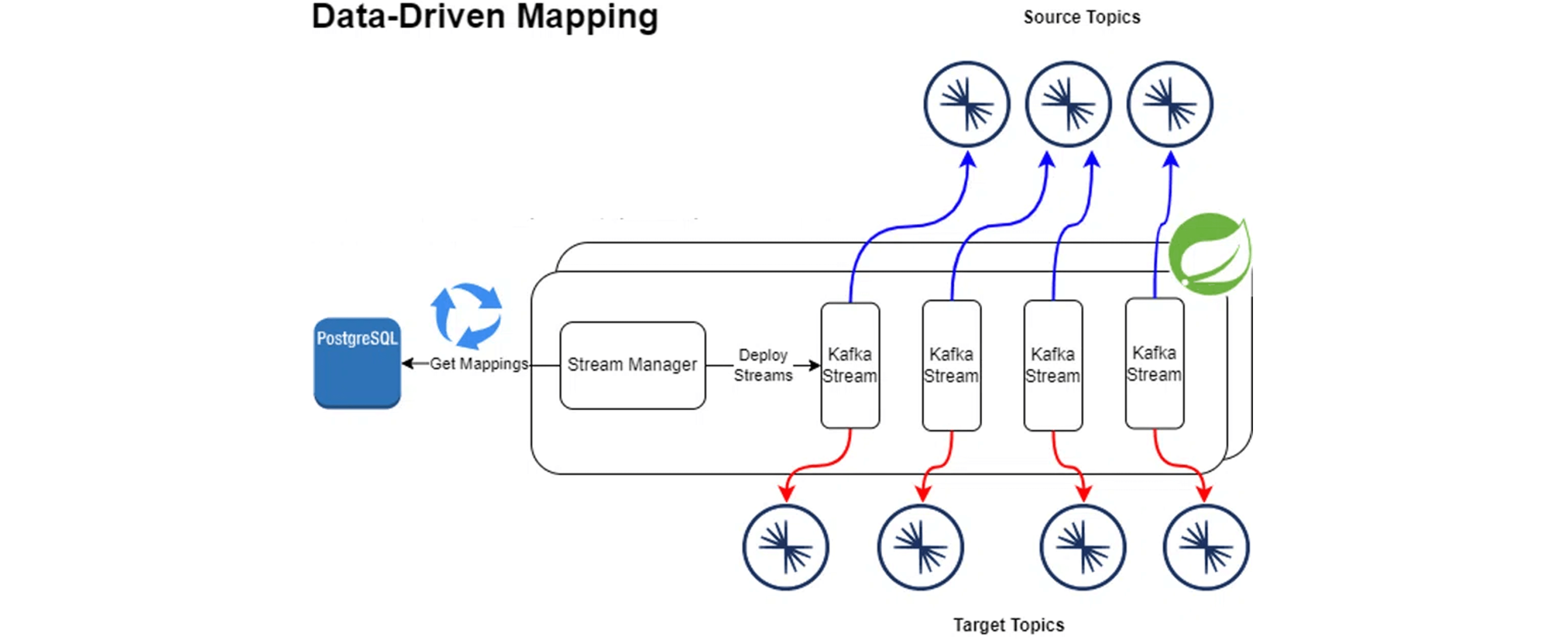
The majority of CDC mappings are simple field-field mappings. Kafka Streams is code-heavy while Flink can be cumbersome for DevOps. All organizations know how to move relational data and already have expertise and tooling in place. Topic-topic mappings are stored in a database, along with their field-field mappings. They are looked up every n seconds, and are applied by the stream manager. They can be scheduled in advance to start or stop. This is a no-code solution, driven by data. Deployments are just data movements, and can be scheduled for a future time:
Debezium monitors the database for changes, produces change events to Confluent Cloud.
CDC events are translated into the target formats and moved to a sink or intermediate topic.
Where more advanced mapping is required, an additional mapping step is applied using Flink.
The connector upserts the data change into the target database(s).
This includes stateless, data-defined streaming transformations.
The data products are a sequence of changes to be reflected in target systems.
Resources
Z/OS Mainframe CDC and Streaming
Contact Us
Contact Matt Hejnas, Architect/Engineer at Converge Technology Solutions, to learn more about this use case and get started.