Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
What is Apache Iceberg™?
Apache Iceberg™ is a high-performance open-source data table format for large analytic datasets. Apache Iceberg brings the simplicity of SQL tables to data lakes with reliability, consistency, performance, and efficiency at scale. Iceberg is openly managed, community-driven, and released under the Apache License.
Apache Iceberg was open-sourced and donated to Apache Software Foundation in November 2018, after being initially developed at Netflix to overcome the challenges of existing table formats. In May 2020, the Iceberg project graduated to become a top-level project in Apache Software Foundation.
Why is Apache Iceberg Important?
Cloud Data Warehouses: One size does not fit all
Data warehouses have been around since the 1980s. In the pre-cloud era, data was extracted, transformed and loaded (ETL) from various operational sources into central data warehouses for reporting and analytics. However, these environments were self-hosted and had tightly integrated storage and compute adding significant overheads for management and scaling.
The next generation of cloud data warehouses (CDW) launched in the early 2010s such as Amazon Redshift, Snowflake, and Google BigQuery separated storage and compute, and were easy to spin up and scale, significantly improving cost efficiency, flexibility, and performance. This kicked off a new paradigm of Extract-Load-Transform (ELT) – all data is loaded into the warehouse first, and then transformed in-place using multi-step medallion bronze-silver-gold architectures.
Cloud data warehouses were largely designed for effective SQL-query based reporting and BI workloads on top of structured, relational data with ACID (atomicity, consistency, isolation, durability) guarantees, enabling data availability, reliability, and usability.
However, as data continued to explode not just in volume but velocity, variety, and applications, the singular dependence and investment into a cloud data warehouse presented new problems:
-
Inability to use the right processing head for the job: Businesses have growing data use cases from training and deploying machine learning models, to ad hoc federated SQL querying, to generative AI applications, not just reporting.
-
Inability to support unstructured and semi-structured data well: ML and AI workloads require large amounts of different types of data that data warehouses are not designed to handle well.
-
Vendor lock-in with proprietary formats: Cloud data warehouses tended to have proprietary file formats for most effective querying that increased vendor lock-in.
-
Redundant data and complexity: It increasingly became common to have both a data lake and a data warehouse, sometimes multiple data stores with medallion data architectures requiring data to be moved and processed repeatedly.
-
Expensive: When all your data and queries run through the cloud data warehouse, storage and/or compute tend to get expensive. Organizations are forced to spend resources optimizing costs or making tough choices on usage.
Cloud Data Warehouses have attempted to address some of these challenges through product innovation. However, changing fundamental constructs is a tough problem to solve. In the meanwhile, other options and solutions evolved to address changing data needs.
Legacy Data Lake Architectures: Slow, Unreliable, and Inefficient Processing with Scale
In the pre-cloud mid 2000s, Apache Hadoop pioneered large-scale distributed data processing such as MapReduce on low-cost file storage, creating the world of open-source data lakes for big data analytics. 1st generation open table formats such as Apache Hive (launched in 2010) introduced SQL and tabular structures into the Hadoop ecosystem.
However, 1st generation open table formats had drawbacks tied to its directory-oriented table format which was too simplistic. A table was just a collection of files tracked at the directory level and query responses were directly tied to that directory structure.
As analytic needs continue to scale, relying on directory-oriented table structures presented significant challenges:
- Performance issues and overheads at scale: Directories needed to perform file list operations which can be slow on datasets with a lot of partitions. Updating or deleting data frequently and schema changes was inefficient and slow because directory-structure table formats necessitated rewriting entire files or datasets.
- Reliability challenges without transaction support: Inability to provide transactional ACID guarantees and unpredictable schema evolution leading to correctness errors. Users were afraid to change data for the risk of breaking something. ACID transactions ensure the highest possible data reliability and integrity ensuring that the information used for analysis is accurate and consistent, even in the event of system failures or concurrent transactions.
Later versions of 1st generation table formats tried to improve upon these drawbacks. However, newer formats emerged to address some of the core architectural concerns.
Apache Iceberg for High-Performance, and Reliable Analytics on Large Data
The challenges with both cloud data warehouses and 1st generation table formats led to the creation and rising popularity of a 2nd generation of Open Table Formats such as Apache Iceberg, Apache Hudi, Delta Lake and Apache Paimon.
While the newer open table formats are similar in capabilities, Apache Iceberg is not tightly tied to any one data ecosystem, allowing it to gain popularity in a world that is embracing open architectures. Apache Iceberg is increasingly solidifying its position as a leading open table format with all major vendors supporting Iceberg format for their workloads, including and not limited to, Spark, Trino, Flink, Presto, Hive, Impala, Snowflake with Polaris catalog, Databricks with Tabular, AWS’s Redshift and S3 Iceberg Tables.
Apache Iceberg enables efficient and faster data management in data lakes by providing features like ACID compliance (atomic, consistent, isolated, durable updates), schema evolution (adding, removing or renaming columns), time travel (accessing historical data version), and allows multiple applications to work on the same data simultaneously while maintaining data consistency across different query engines; essentially bringing the reliability of traditional databases and data warehouses to large-scale data lakes. With Iceberg, organizations can use their low-cost cloud based storage to store all their data in one place and simply swap out the compute engine that is best suited for a particular job.
-
Interoperable, enabling headless data architectures: Iceberg enables seamless interoperability across various compute engines enabling headless data architectures. With a growing number of use cases, organizations can pick and choose the right processing head for the job at hand.
-
Reliable, enabling scale : By guaranteeing ACID compliance and enabling transactions, Iceberg allows multiple query heads to access and run on the same data simultaneously enabling scale. Iceberg also supports schema evolution ensuring correctness. Time-travel ensures that organizations have an immutable history of the data helping with both historical analysis as well as data recovery and regulations.
-
High-performance & efficient: With a detailed metadata layer that ensures that a table is not tied to where the physical file is stored, Iceberg enables reads and writes in an efficient manner, by lowering query planning overheads and removing unnecessary access to files that are not needed.
-
Cost-efficient: Iceberg allows organizations to use lower-cost object or file storage and enable large-scale and efficient analytic workloads without duplicating data into multiple places.
-
Open Standard preventing vendor lock-in: Iceberg enjoys broad ecosystem support that is growing on a daily basis. Being an open format, organizations can future-proof their data architectures and freely move between ecosystems and vendors of their choice.
How does Apache Iceberg work?
Much like how Apache Kafka is built on a foundation of an immutable log containing sequential records of events ordered by time, Apache Iceberg introduced a log-based metadata layer, providing a mutable table layer on top of immutable data files.
Apache Iceberg introduces the manifest file and highly-detailed metadata to solve the problems of previous table formats.
An Iceberg table has three layers:
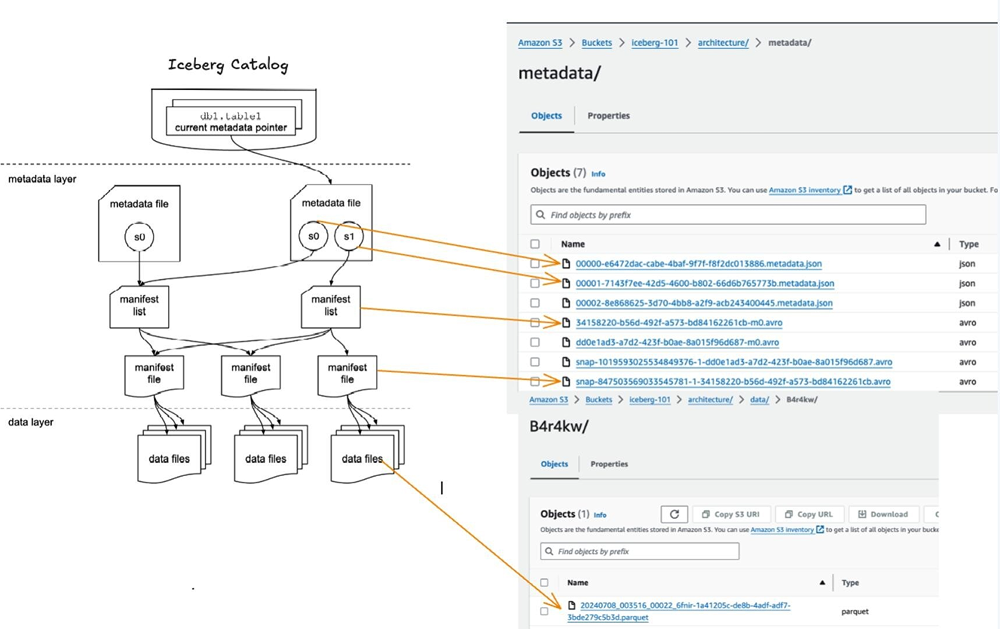
The Data Layer:
This layer is where the actual data for a table is stored; consisting of data files in formats such as Parquet, ORC or Avro. This is where the raw data for queries is located. The layer also stores delete files to handle data deletions without modifying original files.
The data can be stored in low-cost storage by using distributed file systems like Hadoop Distributed File System (HDFS) or cloud object storage solutions such as Amazon S3, Azure Data Lake Storage (ADLS), and Google Cloud Storage (GCS).
Metadata Layer:
Instead of sorting tables into individual directories, Iceberg maintains a list of files. The metadata layer manages table snapshots, schema, and file statistics.
-
Manifest file: It tracks individual data files and delete files. They also provide statistics, including column value ranges that help in query optimization by reducing the need to scan irrelevant files.
-
Manifest list: A list of manifest files that make up a specific snapshot of an Iceberg table at a given point in time. It also summarizes data in manifest files like partition ranges and column statistics allowing query engines to determine which files are relevant.
-
Metadata file: At the top are metadata files that keep track of the table state. It stores the table-wide information: schema, partitioning, and pointers to snapshots. Iceberg supports time travel via snapshots of the table in the past which can be accessed by the manifest list which points to manifest files representing an older version of the table.
The Iceberg Catalog:
The catalog is the central repository that manages Iceberg Tables. It provides a single point of access to discover and manage tables, ensuring data consistency and enabling ACID compliance by providing a pointer to a table’s current metadata file. When updating table metadata, the catalog ensures that change is fully committed before exposing it to other users, enabling atomic updates.
The catalog facilitates table discovery, creation and modification of tables and ensures transactional consistency. By providing a standardized way to interact with Iceberg tables support distributed systems and different data processing engines.
Iceberg supports various catalogs (open and proprietary) such as Iceberg REST catalog, AWS Glue Data Catalog, Apache Polaris, Hive Metastore.
Example paths with the three layers:
Create a new Table
-
Create a metadata file
-
Add a reference to the metadata file in the Catalog
Insert data into the Table (bottom-up)
-
Create new data file
-
Create a manifest file pointing to the data file
-
Create manifest list that points to the manifest file
-
Create a new metadata file with both old snapshot as well as a new snapshot of the table with the insertion of data that points to the manifest list
-
Update the catalog reference to the latest metadata file. The catalog only gets updated if the transaction is successful.
Query from a table (top-down)
-
Get the latest metadata file from the Catalog Layer
-
Use the file statistics and locations to optimize query planning
-
Retrieve only necessary files from the data layer for the query
Reads are top-down enabling efficiency and writes are bottom-up enabling reliability. Snapshots and Manifest Lists enable time travel to previous versions of the tables. And deletes are recorded in the metadata layer without rewriting data files ensuring consistency.
What are the key features of Apache Iceberg?
ACID Transactions on Data Lakes
Iceberg provides robust ACID (Atomicity, Consistency, Isolation, Durability) transaction support to ensure data integrity and reliability in data lakes. This enables multiple independent applications to simultaneously access data in the data lake. When a writer commits a change, Iceberg creates a new, immutable version of the table’s data files and metadata.
Full Schema Evolution
Schema changes (add, drop, rename, reordering, and type promotions) only change the metadata, without the need for data file rewrites or losing historical data.
Hidden Partitioning
Iceberg handles the task of producing partition values for rows in a table ensuring that users don’t have to create or manage additional partitioning columns. Unlike before, users also don’t need to know how the table is partitioned and add extra filters to their queries. By storing partitioning information in the metadata layer versus physical folder structure, Iceberg decouples the logical partitioning scheme from the physical data layout. This allows for evolving partitioning schemes without data rewriting or restructuring. All of this enables better query performance and lower storage costs by minimizing redundant data in files.
Time Travel and Rollback
Allows users to access historical data by querying previous versions of a table, based on snapshots or timestamps. Version rollback allows users to quickly correct problems by resetting tables to a good state.
Expressive SQL support
Iceberg provides advanced SQL capabilities for querying large datasets with ease and efficiency. It handles complex data types, aggregations, filtering, and grouping effectively.
How does Confluent enable Apache Iceberg Tables?
Materialize Kafka Topics as Iceberg Tables with Tableflow
Confluent enables users to easily materialize Kafka topics, and associated schemas into Apache Iceberg tables with push-button simplicity.
Tableflow uses innovations in Confluent’s Kora Storage Layer to take Kafka segments and write them out to other formats, in this case, parquet files. Tableflow also utilizes a new metadata materializer behind the scenes that taps into Confluent’s Schema Registry to generate Apache Iceberg metadata while handling schema mapping, schema evolution, and type conversions automatically. Data quality rules are enforced upstream as part of the contract of the stream itself—incompatible data is forbidden at the source and easily detected in development. Data products flow through directly into the lakehouse and are accessible as both a stream and a table. In addition to schema management, Tableflow also continuously compacts the small parquet files generated by constantly streaming data into larger files to help maintain good read performance.
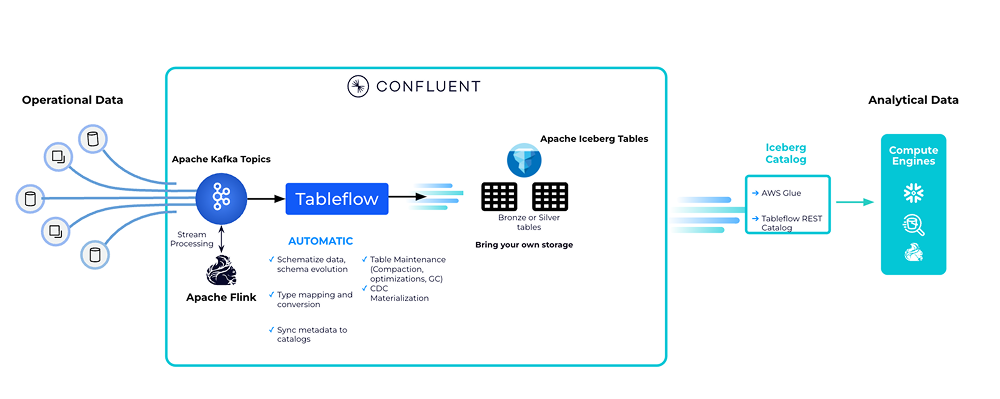
Shift Left to Unify Operations and Analytics with Confluent’s Data Streaming Platform
Data and analytics teams increasingly require access to fresh, reliable, reusable, and contextual data from the operational data estate of custom applications, ERPs, SaaS applications to build meaningful insights and operational teams require analytical and ML insights to directly impact their customer experiences.
However, traditional data architectures keep the two data estates separate and rely on complex, batch-based ETL pipelines that pipe raw or partially cleaned data to downstream systems leading to stale, unreliable, siloed, and redundant data with expensive storage and processing. Shift Left moves data processing and governance closer to the source, bringing real-time, reusable, reliable, and contextual data products anywhere needed including lakehouses, warehouses, or custom applications.
- Real-time data in data lakes with push-button ease: Tableflow unifies the operational and analytical data estate by presenting Kafka topics as Iceberg tables with push-button ease. With Tableflow, data and analytics teams do not need to spend time and resources on manual, brittle, and error-prone jobs to ingest Kafka topics into data lakes. Kafka topics can be accessed as open format Iceberg tables allowing analytics teams to use the query and processing head of choice to run their queries on fresh, real-time data.
- Reliable data through implicit data contract adherence:Tableflow adheres to Confluent’s schema registry, and data quality rules ensuring that the data follows the agreed upon data contract preventing bad data proliferation.
- Reusable, contextual data with Apache Flink: Apache Flink on Confluent along with Tableflow enables teams to unify batch and stream processing unlocking significant value. Flink enables teams to process streaming data (filters, joins, aggregations, and more) and use AI model inference with sophisticated ML models and GenAI LLMs to create reusable and contextual data products which can be presented as Iceberg tables anywhere needed.
- ROI Positive: Confluent’s DSP helps optimize warehouse and lakehose costs by shifting left processing and governance to the left closer to the source to build clean, unified datasets that can be consumed anywhere needed in real-time.
- Open Standards and Interoperability: Built on three leading open-source standards (Kafka, Flink, Iceberg), the Data Streaming Platform provides unified, secure data access across operational and analytical systems. This enables application developers, data engineers, and analytics teams to work with data in their preferred formats and programming languages like SQL, Python or Java.