Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
How to Efficiently Subscribe to a SQL Query for Changes
Imagine that you have real-time data about what’s happening in the stock market, and you want to support a large number of customized dashboards displaying the data as it comes in. Conceptually, each dashboard has a query and every incoming event matching the query is a new data point. That’s simple enough, but how would you implement the backend system?
The most straightforward solution is to put that data into a traditional database where it can be queried. To be done efficiently, indexes would be set up on the relevant dashboard fields and timestamps, allowing for key-based lookups. Then the dashboards would poll each of the queries, every period of time. This works, but there are limitations: referencing an unindexed attribute or polling too frequently can use a lot of resources and degrade performance.
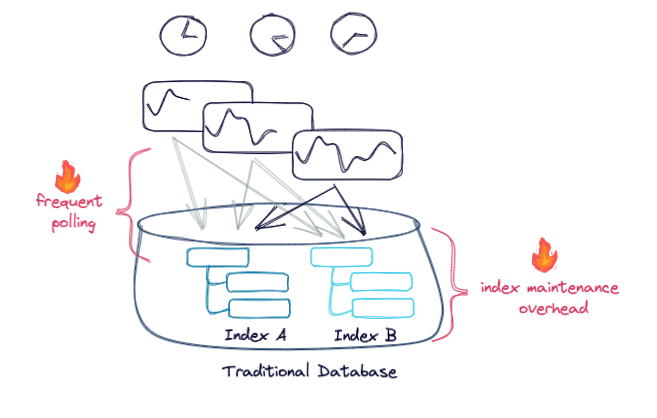
Point-in-time lookups are valuable at the outset for “backfilling” historical data, but less optimal for maintaining the application with updates. An improvement for the latter could be to only render the latest events, a perfect problem for Apache Kafka® to solve.
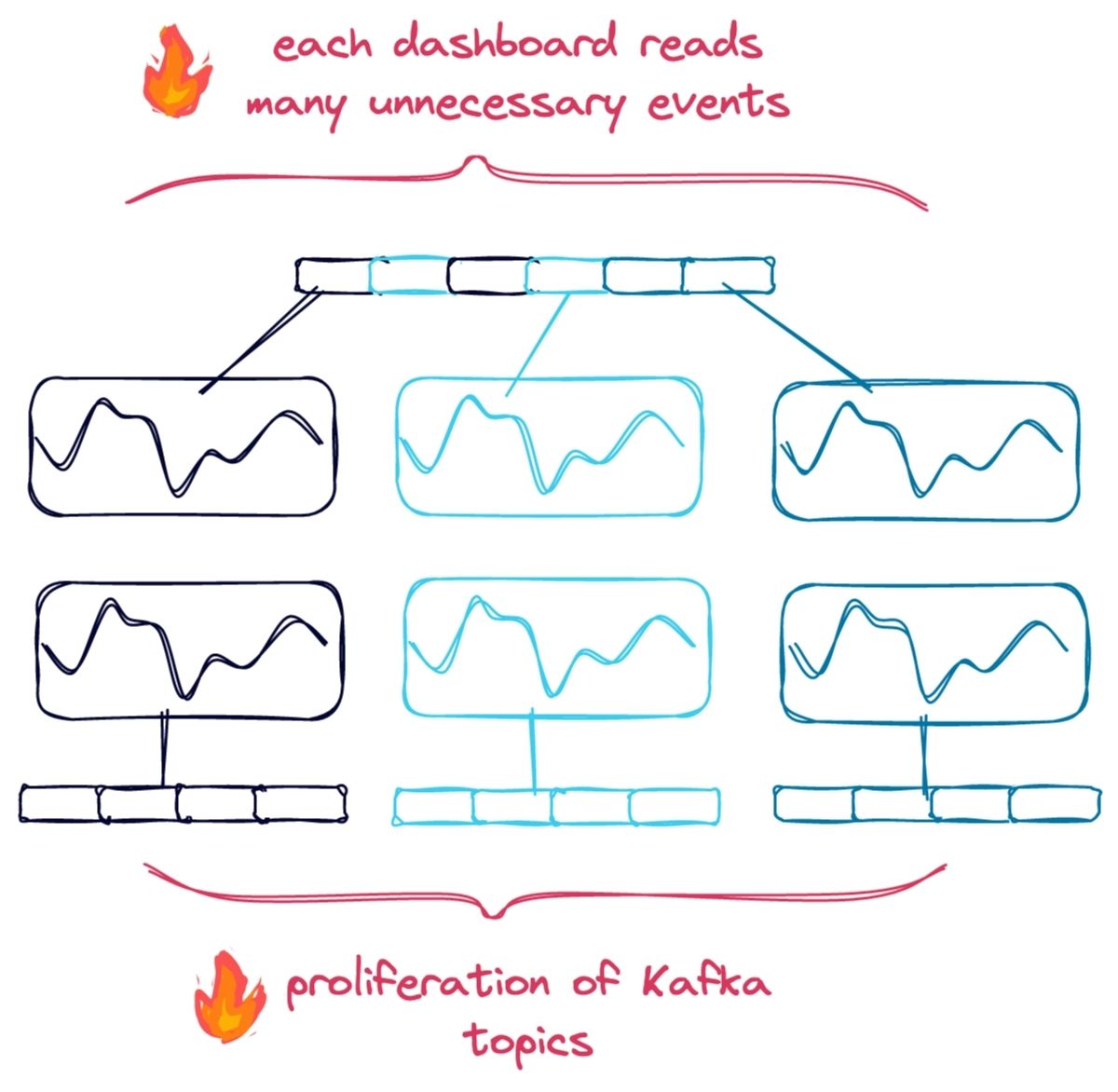
Let’s say we have a Kafka topic trades with our input events. A solution to our above problem might try to segment the data into topics with filters applied, e.g., we would read trades and output events to trades_equities and trades_bonds with a stream processing application, allowing dashboards to consume events from the topics matching their filters. Unfortunately, the number of unique combinations and resulting topics could be quite large, making this approach impractical. Similarly, a dashboard could consume trades directly and evaluate events against its queries, but this doesn’t scale very well since every dashboard would consume all of the data from Kafka. Again, there are limitations: neither scales well, and both require a custom application to implement filtering logic and orchestrate query updates.
A final improvement could be a more generalized form of the last approach where for each input event from the topic trades, we match it against all of the registered queries in the system, allowing only a single pass over the topic. Note that this is precisely the inverse of a traditional database where we match many rows against an individual query. This would amount to on-the-fly server-side filtering for the topic and allow us to take advantage of the incremental nature of real-time processing without having to know the query pattern ahead of time.
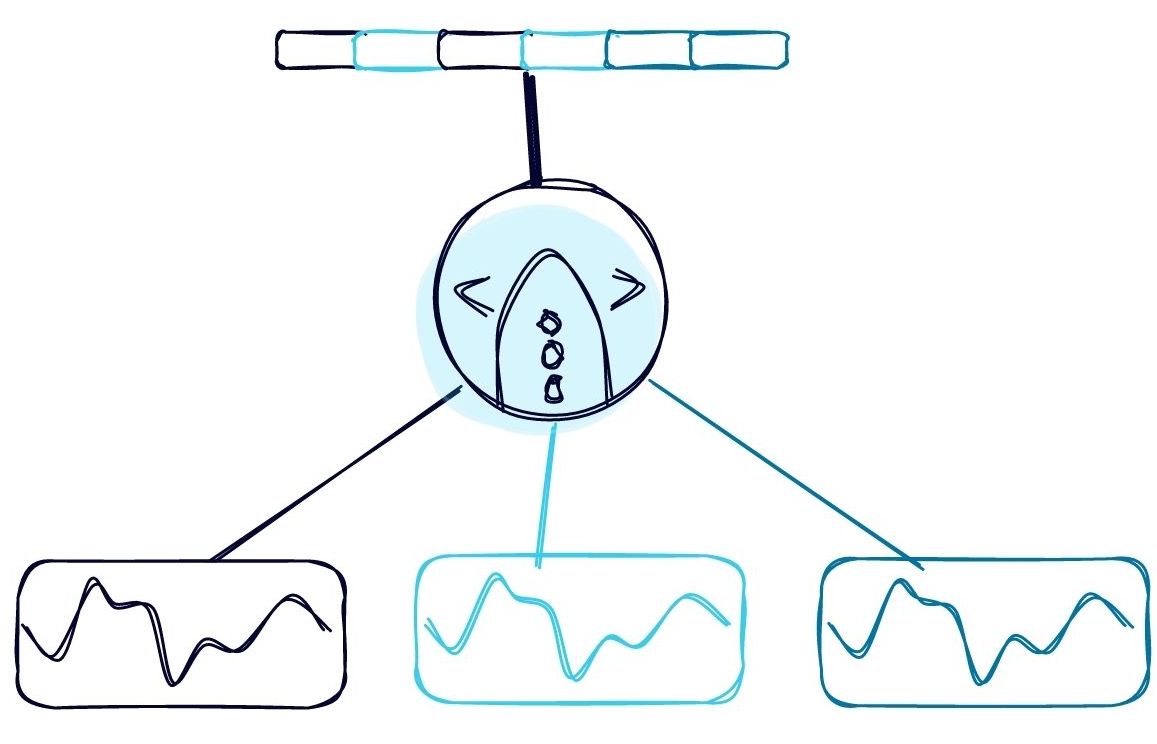
We’ve noticed that there aren’t many solutions that use this final approach, and we’re not the only ones. Kafka has had community interest in broker-side filtering and RethinkDB pioneered some of this thinking with changefeeds. ksqlDB, a database for stream processing, now builds on these ideas by combining the flexibility of a traditional database with the power of a purpose-built Kafka solution, like the one outlined above.
Efficiently subscribe to a SQL query with ksqlDB
ksqlDB supports a subscription mechanism called push queries that allows matching rows to be queried in exactly this manner. Up to this point, the number of concurrent queries that it supports has been limited. Starting with Confluent Cloud and ksqlDB 0.22, it can now support larger scale use cases with push queries v2. These queries allow:
- Up to 1,000 concurrent subscriptions, per ksqlDB server instance, across numerous clients (This is an estimate and depends on the rate of data production)
- Lightweight on-the-fly matching using the query WHERE clause
- Easy subscription lifetime management lasting the life of a query
- Best effort message delivery
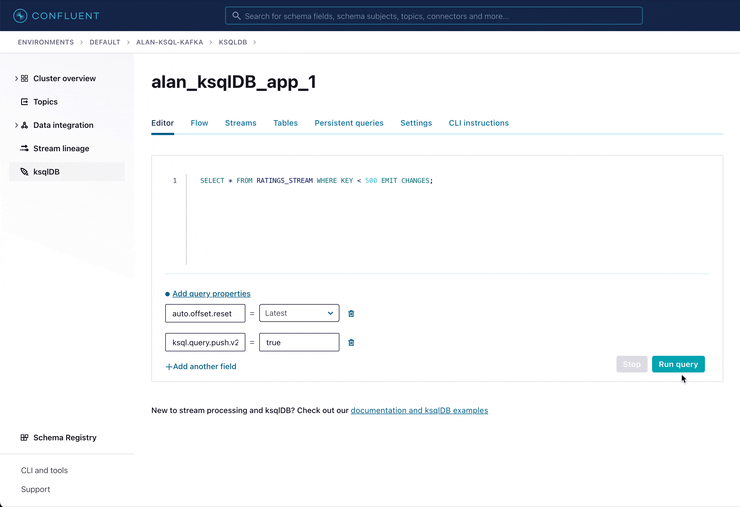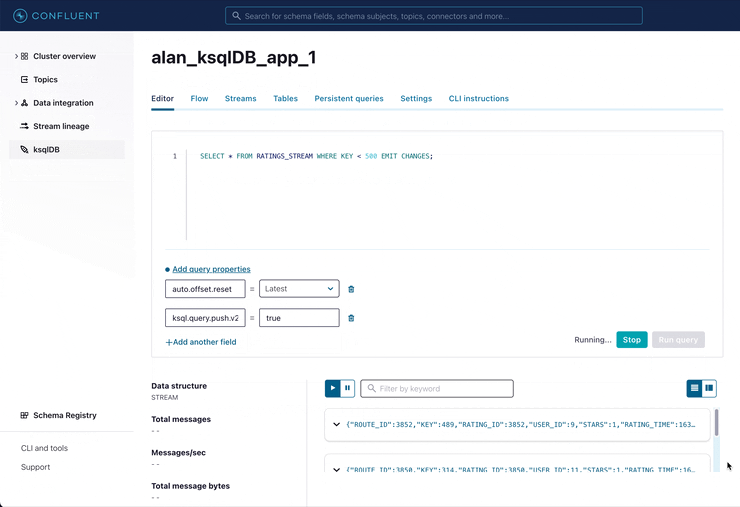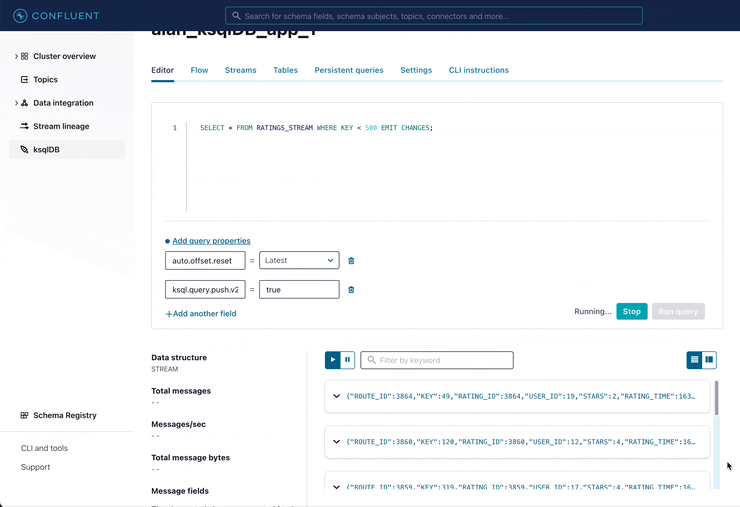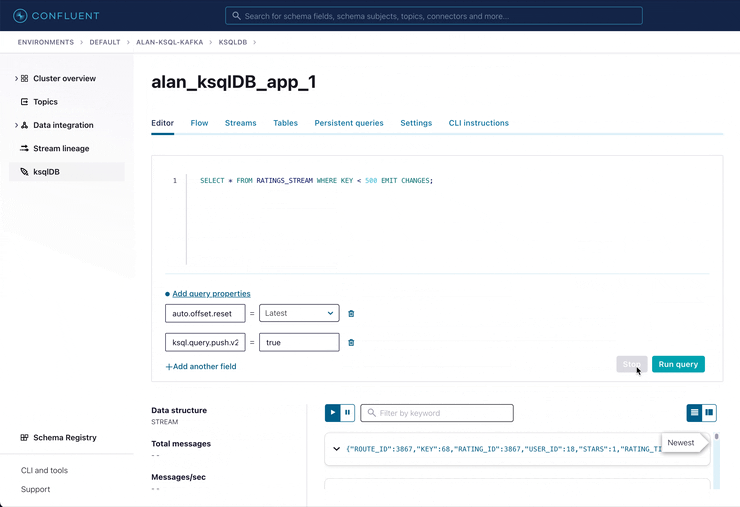
Let us consider again our above example. Suppose we have created the following stream and table in ksqlDB:
CREATE STREAM TRADES( TRADE_ID BIGINT KEY, ASSET_TYPE STRING, ASSET_NAME STRING, TRADE_TYPE STRING, VALUE DOUBLE ) WITH ( KAFKA_TOPIC='trades', VALUE_FORMAT='JSON', partitions=32 );
-- Creates a table for querying historical data as well as -- issuing subscriptions. CREATE TABLE TRADES_WINDOWED AS SELECT ASSET_NAME, LATEST_BY_OFFSET(ASSET_TYPE) AS ASSET_TYPE, SUM(VALUE) AS TOTAL_VALUE FROM TRADES WINDOW TUMBLING (SIZE 5 SECONDS) GROUP BY ASSET_NAME;
We’re interested in using TRADES_WINDOWED in our dashboard and using it to display trades aggregated into five second windows. We can first backfill the data with a pull query (ksqlDB’s equivalent of a point-in-time query), and then issue the following push query to display just equities where the total trade value is greater than 1,000:
-- Backfill data first with a pull query SELECT * FROM TRADES_WINDOWED WHERE ASSET_TYPE = 'equity' AND TOTAL_VALUE > 1000.0 AND WINDOWSTART > '2021-08-18T00:00:00.010';
-- Now keep up to date with a similar push query -- (note the EMIT CHANGES clause) SET 'auto.offset.reset' = 'latest'; SET 'ksql.query.push.v2.enabled' = 'true'; SELECT * FROM TRADES_WINDOWED WHERE ASSET_TYPE = 'equity' AND TOTAL_VALUE > 1000.0 EMIT CHANGES;
This push query is run with none of the limitations we described for the potential solutions above. Similar queries could be scaled up across 1,000 visualizations and dashboards, per ksqlDB server, without exploding the number of times we read the data in TRADES_WINDOWED or creating any new topics. Similarly, we’re not limited to querying by primary key—any column can be referenced. It should be noted that the same non-key performance issues that exist with conventional databases could also affect pull queries, though in a backfill scenario, it must be run just once and state updates can then be maintained efficiently with a push query.
In many ways, this is not unlike subscribing to Kafka directly for the topic TRADES_WINDOWED, but rather than being limited to the data as it was written by the persistent query, we can rely on a SQL expression to server-side filter and compute columns, giving a customized view into the data.
How it works
We wanted an architecture that scales horizontally with each server in the ksqlDB cluster, without having to read all of the input data separately for each request. To utilize this new scalable codepath, push queries v2 require that a push query select from an existing persistent query (TRADES_WINDOWED in the above example), which for background, is an always-running stream processing job consuming and producing data to Kafka. The push query execution engine is co-located with every task processing that persistent query, ensuring that no additional data movement is required. For each task, each row output is matched against all of the registered push queries.
The registered queries are dynamically maintained, ensuring processing is done for only live queries running at that moment. Matching rows are fed back to the originating server and then to the client, while ensuring the operation is stopped and cleaned up when the request is completed.
Note that persistent query tasks can be rebalanced to different servers in the cluster and the currently live push queries must pick up on these changes when they happen. This is most notable when a new server joins the cluster or an existing one leaves. The originating server creates a connection to a new server to register the push query to ensure continuity and similarly deregisters and closes the connection to a leaving server.
Push queries v2
Like our previous iteration of push queries, these queries are perfect for applications with shorter lifespans, but because they are passively consuming data which has already been processed and it’s shared between many requests, there’s very little overhead. In fact, the new scaling benefits happen transparently when they can be applied—otherwise you get the same push queries as before. To enable this feature, the config ksql.query.push.v2.enabled=true must be set in the query request.
Limitations
To utilize the scaling improvements, the following limitations are placed on your query:
- No GROUP BYs, PARTITION BYs, or windowing expressions
- Must read newly arriving data only; e.g., SET 'auto.offset.reset' = 'latest' (i.e., cannot read historical data yet)
- Must have only a single upstream persistent query
We have future plans to lift some of these limitations, namely the need to start with only the latest. We’d like a query to be able to start where it last left off, after a network disruption or other fault, or even at an arbitrary timestamp. This should allow:
- At-least-once message delivery, even with faults
- Historical backfilling by timestamp—no need to use a pull query to get historical data if you’re not going far back
Lightweight queries on real-time data are no longer confined to looking up entries in a conventional database table—they can now be done on data streams with all of the same convenience and familiarity. Give them a try with ksqlDB today.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.