Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Keys in ksqlDB, Unlocked
One of the most highly requested enhancements to ksqlDB is here! Apache Kafka® messages may contain data in message keys as well as message values. Until now, ksqlDB could only read limited kinds of data from the key position. ksqlDB’s latest release—ksqlDB 0.15—adds support for many more types of data in messages keys, including message keys with multiple columns. Users of Confluent Cloud ksqlDB already have access to these new features as Confluent Cloud always runs the latest release of ksqlDB.
ksqlDB 0.15 supports message keys:
- In all supported serialization formats: JSON, AVRO, PROTOBUF, DELIMITED, KAFKA, and JSON_SR
CREATE STREAM my_stream (my_key BIGINT KEY, v1 STRING, v2 INT)
WITH (KAFKA_TOPIC='my_topic', KEY_FORMAT='PROTOBUF', VALUE_FORMAT='JSON');
- With structured data types, such as ARRAY, STRUCT, and nested combinations, in addition to previously supported types: STRING, INTEGER, BIGINT, DOUBLE, DECIMAL, and BOOLEAN
CREATE STREAM my_other_stream (
my_key STRUCT<f1 INT, f2 STRING> KEY, v1 STRING, v2 INT
) WITH (KAFKA_TOPIC='my_topic', FORMAT='JSON');
- Consisting of multiple columns, i.e., composite keys
CREATE STREAM my_other_stream (
k1 STRING KEY, k2 BOOLEAN KEY, v1 STRING, v2 INT
) WITH (KAFKA_TOPIC='my_topic', FORMAT='JSON');
Additionally, ksqlDB now also supports PARTITION BY and GROUP BY multiple partitioning or grouping expressions, resulting in tables and streams with multiple key or primary key columns, respectively.
CREATE STREAM my_repartitioned_stream AS
SELECT my_key->f1 AS k1, v1 AS k2, v2
FROM my_other_stream
PARTITION BY my_key->f1, v1
EMIT CHANGES;
CREATE TABLE my_aggregate AS
SELECT k1, k2, COUNT(*) AS cnt
FROM my_repartitioned_stream
GROUP BY k1, k2
EMIT CHANGES;
Let’s dive into each of these enhancements in turn.
New serialization formats
All value serialization formats supported by ksqlDB may now be used as key formats as well. ksqlDB users are familiar with specifying a value format when creating streams and tables:
CREATE STREAM my_stream (...) WITH (KAFKA_TOPIC='my_topic', VALUE_FORMAT='JSON');
To specify a key format, use the new KEY_FORMAT property:
CREATE STREAM my_stream (...) WITH (KAFKA_TOPIC='my_topic', KEY_FORMAT='KAFKA', VALUE_FORMAT='JSON');
If your key and value formats are the same, the FORMAT property can be used in lieu of specifying the two separately:
CREATE STREAM my_stream (...) WITH (KAFKA_TOPIC='my_topic', FORMAT='JSON');
If either the key format or value format is unspecified, then the default formats will be used. Default key and value formats are controlled by the ksql.persistence.default.format.key and ksql.persistence.default.format.value configs, respectively. In a ksqlDB server configuration file, this could be the following:
ksql.persistence.default.format.key=KAFKA ksql.persistence.default.format.value=AVRO
Or, equivalently in a Docker Compose file:
ksqldb-server:
image: confluentinc/ksqldb-server:0.15.0
...
environment:
KSQL_LISTENERS: http://0.0.0.0:8088
KSQL_BOOTSTRAP_SERVERS: broker:9092
...
KSQL_KSQL_PERSISTENCE_DEFAULT_FORMAT_KEY: KAFKA
KSQL_KSQL_PERSISTENCE_DEFAULT_FORMAT_VALUE: AVRO
By default, ksql.persistence.default.format.key is set to KAFKA, so statements that do not specify an explicit key format continue to function as in older ksqlDB versions. The ksql.persistence.default.format.value config has no default. Unless it is set, CREATE STREAM and CREATE TABLE statements that do not specify an explicit value format will be rejected.
For additional details on these new key formats, including how to use schema inference to infer key schemas, see the section covering implications of the new key formats on schema inference and joins.
Expanded data type support
In addition to expanding the set of supported key serialization formats, ksqlDB 0.15 also adds support for additional data types for message keys. The ARRAY and STRUCT data types are now accepted as valid key column data types, as well as nested combinations of such:
CREATE STREAM my_stream (K STRUCT<array_field ARRAY<INTEGER>, other_field STRING> KEY, V BIGINT) WITH (KAFKA_TOPIC='my_topic', FORMAT='JSON');
Note that nested types including ARRAY and STRUCT are not supported by certain serialization formats, such as KAFKA and DELIMITED.
ksqlDB does not support MAP type keys as maps may experience inconsistent serialization, which could lead to unexpected behavior if logically equivalent keys are not sent to the same topic partition and are processed by different processors as a result. For the same reason, nested types containing maps are also not supported as key column data types.
Single field wrapping
For all formats other than PROTOBUF, ksqlDB expects that if a schema is declared with a single key column, then that key column is unwrapped, which means the contents are not contained in an outer record or object. For example, a JSON integer is unwrapped while a JSON object containing a single integer field is wrapped.
As such, a JSON stream declared with the schema (K INTEGER KEY, V STRING) will fail to deserialize keys such as the following:
{
"K" : 123
}
In order to properly use such message keys with ksqlDB, instead declare the key schema as a STRUCT to indicate that the key field is wrapped:
CREATE STREAM my_stream (MY_KEY STRUCT<K INTEGER> KEY, V STRING) WITH (KAFKA_TOPIC='my_topic', FORMAT='JSON');
Multiple key columns
Wrapped keys with multiple fields may also be represented as multiple key columns. For example, if your message keys look like this:
{
"K1" : "foo",
"K2" : 42
}
Then you have two options for how to represent your keys in ksqlDB. The following are both valid:
(MY_KEY STRUCT<K1 STRING, K2 INTEGER> KEY, [... value columns ...])(K1 STRING KEY, K2 INTEGER KEY, [... value columns ...])
These two are equivalent, though their downstream usage looks different syntactically. Here’s an example of copying the first key column into the message value (without changing the message key), using the first key representation:
CREATE STREAM stream_copy AS SELECT MY_KEY, AS_VALUE(MY_KEY->K1) FROM my_stream EMIT CHANGES;
And here’s the equivalent query using the second key representation:
CREATE STREAM stream_copy AS SELECT K1, K2, AS_VALUE(K1) FROM my_stream EMIT CHANGES;
When ksqlDB performs schema inference to auto-populate key columns from the latest schema in Confluent Schema Registry (see Integration with Confluent Schema Registry below), ksqlDB uses the first of the two equivalent representations (with key column name ROWKEY). If you prefer the latter representation instead, you can specify the key schema explicitly rather than rely on schema inference.
Note that the KAFKA serialization format does not support multiple key columns, as the format supports neither the STRUCT type nor serializing multiple columns.
PARTITION BY multiple expressions
ksqlDB now supports PARTITION BY clauses with multiple partitioning expressions:
CREATE STREAM repartitioned_stream AS SELECT * FROM my_stream PARTITION BY <expression 1>, <expression 2> EMIT CHANGES;
This query results in two key columns, where the first corresponds to <expression 1> and the second corresponds to <expression 2>. The name of each key column is determined as follows:
- If the partitioning expression is a single source column reference, then the name of the corresponding key column will be that of the source column
- If the partitioning expression is a reference to a field within a STRUCT-type column, then the name of the corresponding key column will be the name of the STRUCT field
- If the partitioning expression is any other expression, then the key column will have a system generated name, similar to KSQL_COL_0
Because the KAFKA serialization format does not support multiple columns, PARTITION BY multiple expressions is not supported for the KAFKA key format. If desired, you can specify a different key format as part of your query:
CREATE STREAM repartitioned_stream WITH (KEY_FORMAT='JSON') AS SELECT * FROM my_stream PARTITION BY <expression 1>, <expression 2> EMIT CHANGES;
GROUP BY multiple expressions
With the introduction of support for multiple key columns in ksqlDB 0.15, queries with GROUP BY clauses that contain multiple grouping expressions now result in multiple primary key columns, rather than a single primary key column that is the string concatenation of the different expressions.
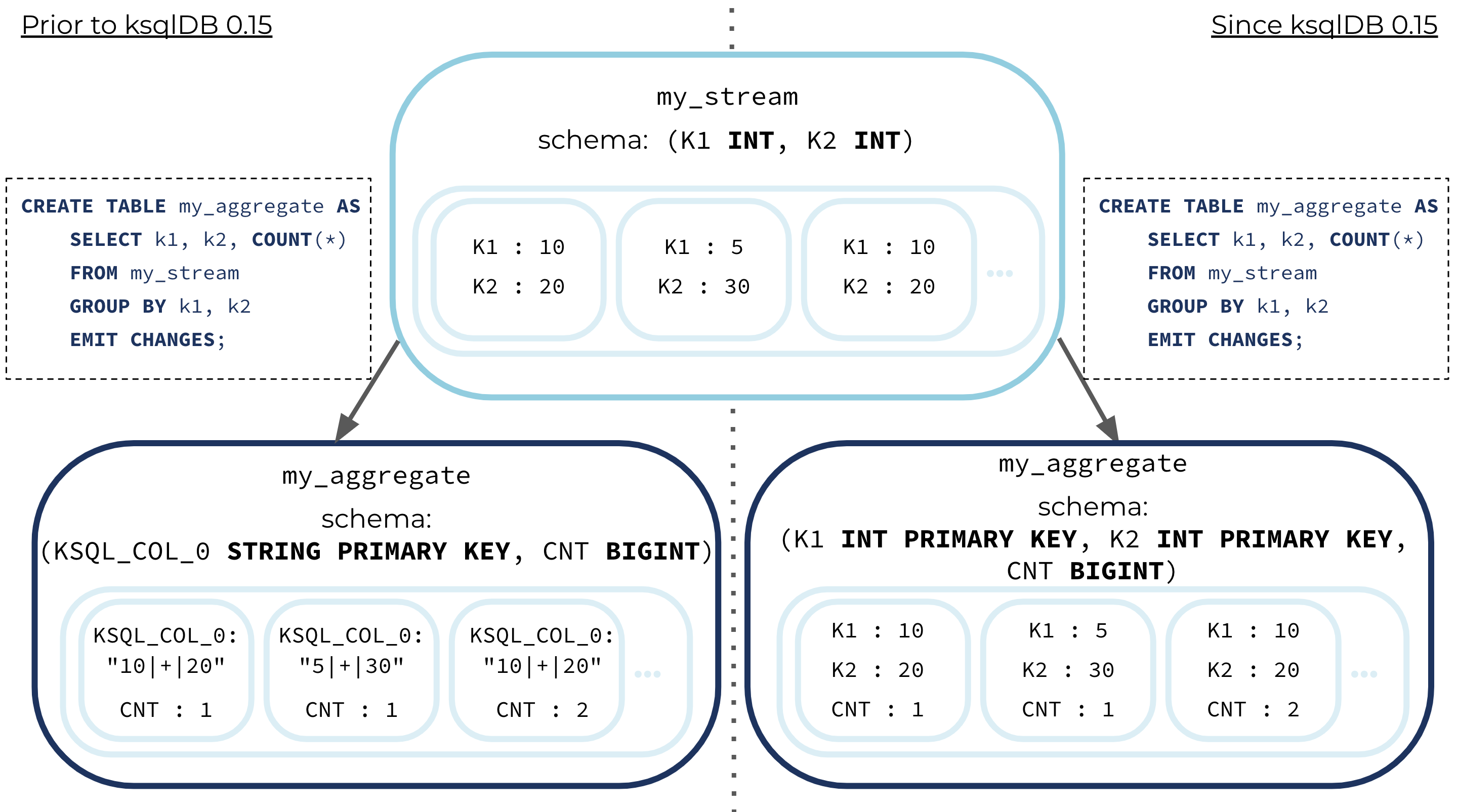
As of ksqlDB 0.15, tables created from queries that GROUP BY multiple expressions have multiple primary key columns, one for each grouping expression.
Concretely, consider the following query:
CREATE TABLE my_aggregate AS SELECT K1, K2, COUNT(*) AS CNT FROM my_stream GROUP BY K1, K2 EMIT CHANGES;
Prior to ksqlDB 0.15, the GROUP BY clause with multiple grouping expressions resulted in a single key column with a system generated name, KSQL_COL_0, and type STRING.
As of ksqlDB 0.15, the equivalent query instead results in a table with two primary key columns, with names K1 and K2, and data types corresponding to the original K1 and K2 columns. More generally, the number of resulting primary key columns matches the number of grouping expressions, and the data type of each primary key column is as specified by the grouping expression. The rules for determining the names of the resulting primary key columns are the same as those for PARTITION BY described above.
Upgrading and compatibility implications
Though the behavior of GROUP BY on multiple expressions has changed in ksqlDB 0.15, persistent queries issued prior to ksqlDB 0.15 will continue to run with the old behavior. In other words, in-place upgrades from ksqlDB 0.14 to 0.15 are supported. If you are a Confluent Cloud customer using ksqlDB, you can start using the new features right away as Confluent Cloud ksqlDB clusters have already been upgraded. Newly issued queries will have the new behavior.
Additionally, because the KAFKA serialization format does not support multiple columns, GROUP BY multiple expressions is no longer supported for the KAFKA key format. Existing persistent queries will continue to run undisrupted, but new queries of this type will be rejected.
If desired, you can specify a different key format as part of your query:
CREATE TABLE my_aggregate WITH (KEY_FORMAT='JSON') AS SELECT K1, K2, COUNT(*) AS CNT FROM my_stream GROUP BY K1, K2 EMIT CHANGES;
Or, you can replicate the old behavior by manually creating a single grouping expression from the individual expressions, and aliasing the resulting key column to have the old system generated name:
CREATE TABLE my_aggregate AS
SELECT
CAST(K1 AS STRING) + '|+|' + CAST(K2 AS STRING) AS KSQL_COL_0,
COUNT(*) AS CNT
FROM my_stream
GROUP BY CAST(K1 AS STRING) + '|+|' + CAST(K2 AS STRING)
EMIT CHANGES;
Implications for pull queries
To issue pull queries against tables created as the result of an aggregation with multiple expressions in the GROUP BY clause, you can use a conjunction of equality expressions to cover the different primary key columns. Given the table below:
CREATE TABLE my_aggregate AS SELECT K1, K2, COUNT(*) AS CNT FROM my_stream GROUP BY K1, K2 EMIT CHANGES;
An example pull query is as follows:
SELECT * FROM my_aggregate WHERE K1='foo' AND K2='bar';
As of today, values must be specified for all primary key columns as part of the pull query.
JOIN on sources with multiple key columns
ksqlDB 0.15 does not add support for JOIN on sources with multiple key columns. If desired, you can work around this limitation by creating a single STRUCT-type key column for your sources instead of declaring multiple key columns.
For source streams and tables, this means declaring the key schema as:
(MY_KEY STRUCT<K1 STRING, K2 INTEGER> KEY, [... value columns ...])
Rather than:
(K1 STRING KEY, K2 INTEGER KEY, [... value columns ...]).
For PARTITION BY multiple expressions, this means the following:
CREATE STREAM repartitioned_stream AS SELECT * FROM my_stream PARTITION BY STRUCT(K1 := <expression 1>, K2 := <expression 2>) EMIT CHANGES;
Rather than:
CREATE STREAM repartitioned_stream AS SELECT * FROM my_stream PARTITION BY <expression 1>, <expression 2> EMIT CHANGES;
Finally, for GROUP BY multiple expressions, this means:
CREATE TABLE my_aggregate AS
SELECT
STRUCT(K1 := <expression 1>, K2 := <expression 2>) AS K,
COUNT(*) AS CNT
FROM my_stream
GROUP BY STRUCT(K1 := <expression 1>, K2 := <expression 2>)
EMIT CHANGES;
Instead of:
CREATE TABLE my_aggregate AS
SELECT
<expression 1> AS K1,
<expression 2> AS K2,
COUNT(*) AS CNT
FROM my_stream
GROUP BY <expression 1>, <expression 2>
EMIT CHANGES;
Implications of new key formats on schema inference and joins
This section covers additional details of the newly supported key serialization formats, including how you can use schema inference with keys and how ksqlDB joins sources with different key formats.
Integration with Confluent Schema Registry
The AVRO, PROTOBUF and JSON_SR ksqlDB serialization formats require your ksqlDB cluster to be integrated with Confluent Schema Registry. For users of Confluent Cloud, this integration happens automatically when you stand up a new ksqlDB cluster, as long as you have enabled Schema Registry in your environment.
| ℹ️ | Note that JSON and JSON_SR are distinct: The JSON format is not integrated with Schema Registry, while JSON_SR benefits from schema management and ksqlDB schema inference due to its integration with Schema Registry. See the documentation for more. |
For self-managed ksqlDB users, integrating ksqlDB with Schema Registry is as simple as configuring the address of a Schema Registry cluster in the ksqlDB server properties via the ksql.schema.registry.url config. Once configured, ksqlDB can infer column names and types of messages in Kafka topics so that you no longer need to specify schemas explicitly in CREATE STREAM and CREATE TABLE statements. This is called schema inference.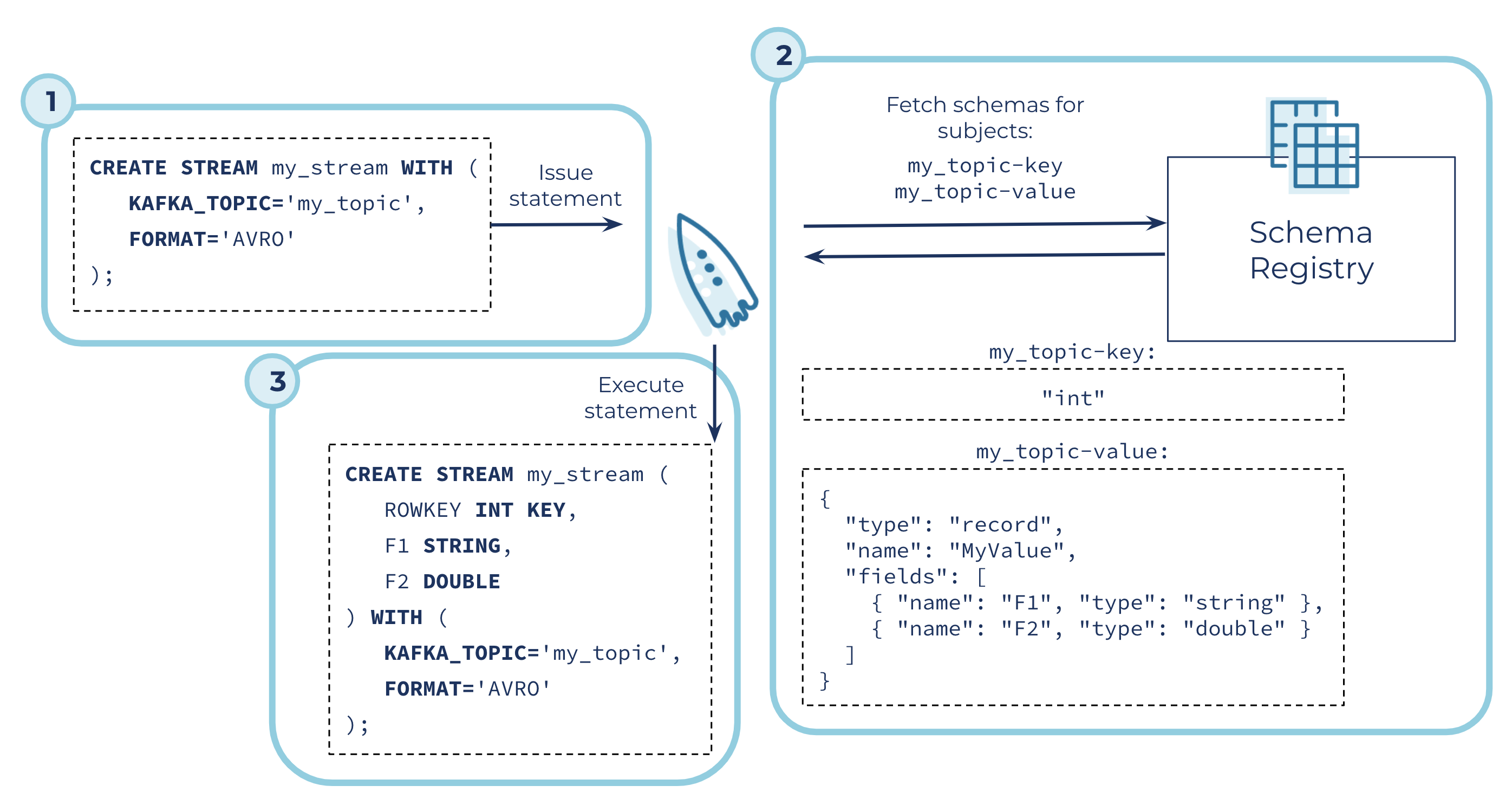
ksqlDB performs schema inference by fetching the latest key and value schemas from Confluent Schema Registry.
Assuming that the following Avro schema is registered under the Schema Registry subject my_topic-key:
"int"
And the following Avro schema is registered under the subject my_topic-value:
{
"type": "record",
"name": "MyValue",
"fields": [
{
"name": "F1",
"type": ["null", "string"]
},
{
"name": "F2",
"type": ["null", "double"]
}
]
}
Then executing the following ksqlDB statement:
CREATE STREAM my_avro_stream WITH (KAFKA_TOPIC='my_topic', FORMAT='AVRO');
Will result in the new stream having the inferred schema (ROWKEY INT KEY, F1 STRING, F2 DOUBLE).
If no key columns are desired, the KEY_FORMAT may be set to the special value NONE to indicate that no key schema inference should be attempted. The following statement will infer value column names and types from Schema Registry but not key columns. This is called partial schema inference.
CREATE STREAM my_avro_valued_stream WITH (KAFKA_TOPIC='my_topic', KEY_FORMAT='NONE', VALUE_FORMAT='AVRO');
Partial schema inference also works in the other direction. Here’s an example that infers the key schema but not the value schema, as the value’s JSON format does not support schema inference:
CREATE STREAM my_json_valued_stream (V1 BIGINT, V2 ARRAY<STRING>) WITH (KAFKA_TOPIC='my_topic', KEY_FORMAT='AVRO', VALUE_FORMAT='JSON');
Assuming the same schema registered under the subject my_topic-key as above, the newly created stream will have the schema (ROWKEY INT KEY, V1 BIGINT, V2 ARRAY<STRING>).
Automatic repartitioning for joins
When joining two sources (i.e., streams or tables) of data, the two sources must be co-partitioned. This requires that the keys of the two sources be serialized in the same way, which in turn requires that they have the same data types and formats. Similar to how ksqlDB will automatically repartition streams to enable joins, if joining on an expression that is not the stream’s key, ksqlDB will also automatically repartition sources to enable joins where the key formats of the two sources do not match.
For example, if source A has key format KAFKA and source B has key format AVRO, and you issue a statement that requires joining the two sources, then ksqlDB will automatically repartition one of the two sources to enable the join. Note that this is true even if both A and B are tables. ksqlDB does not support repartitioning tables except when the only change is the key format. This is because Apache Kafka only guarantees order within each topic partition, so unless there is a one-to-one correspondence between the new key (post-repartition) and the old key (pre-repartition), then repartitioning a table could result in table updates being reordered.
This is not a concern when the only difference between the old and new keys is the serialization format; it is safe to repartition in this case, and ksqlDB will do so automatically as a convenience for users.
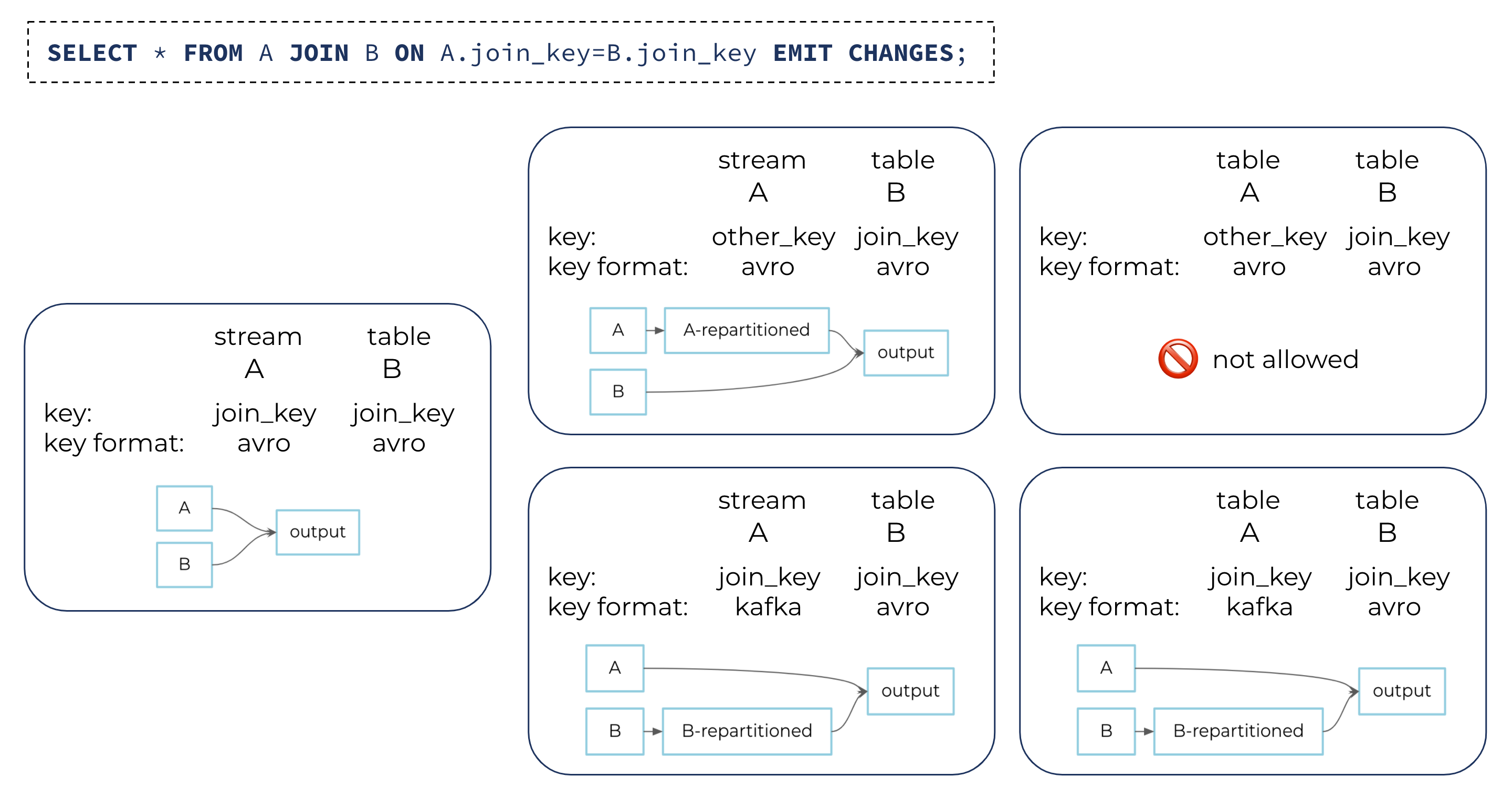
Similar to how ksqlDB ensures co-partitioning by automatically repartitioning streams when joining on an expression other than the stream’s key columns, ksqlDB also automatically repartitions streams and tables when the two sides of the join have different key formats.
What’s next for ksqlDB
The first phase of expanded support for message keys in ksqlDB is complete, but there’s still plenty more to come:
- Enhanced pull query support on tables with multiple key columns
- Joins on streams and tables with multiple key columns
- A new BYTES type to represent arbitrary binary data, useful for both key and value columns
In addition to the incremental improvements above, the team is also exploring a number of larger changes to ksqlDB semantics:
- The potential for joins to retain join expressions from both sides of the join condition(s) in the message key, rather than requiring they be copied to the value in order to be accessible in the result.
- Removal of the requirement that all key columns be present in the SELECT expressions for persistent queries.
- Removal of the requirement that all key columns are named.
- More seamless conversion between tables and changelog streams, including proper handling of tombstones in the process—for example, CREATE TABLE my_table AS SELECT TABLE(my_stream); and SELECT * FROM STREAM(my_table);.
- Improved handling of out-of-order data, such as versioned tables that allow users to query older points in time (SELECT … AS OF <timestamp>;) and also allow for more predictable join results.
Get started!
Ready to check ksqlDB out? Head over to ksqldb.io to get started, where you can follow the quick start, read the docs, and learn more! For more on what’s new in ksqlDB 0.15, see the changelog or blog post.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.