Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Internet of Things (IoT) and Event Streaming at Scale with Apache Kafka and MQTT
The Internet of Things (IoT) is getting more and more traction as valuable use cases come to light. A key challenge, however, is integrating devices and machines to process the data in real time and at scale. Apache Kafka® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and ksqlDB, have become the technology of choice for integrating and processing these kinds of datasets.
Kafka-native options to note for MQTT integration beyond Kafka client APIs like Java, Python, .NET, and C/C++ are:
- Kafka Connect source and sink connectors, which integrate with MQTT brokers in both directions
- Confluent MQTT Proxy, which ingests data from IoT devices without needing a MQTT broker
- Confluent REST Proxy for a simple but powerful HTTP-based integration
Before I discuss these in more detail, let’s take a look at some common use cases where Confluent Platform and Confluent Cloud are used for IoT projects today.
Use cases for IoT technologies and an event streaming platform
Confluent Platform and Confluent Cloud are already used in many IoT deployments, both in Consumer IoT and Industrial IoT (IIoT). Most scenarios require a reliable, scalable, and secure end-to-end integration that enables bidirectional communication and data processing in real time. Some specific use cases are:
- Connected car infrastructure: cars communicate with each other and the remote datacenter or cloud to perform real-time traffic recommendations, prediction maintenance, or personalized services.
- Example: Audi
- Smart cities and smart homes: Buildings, traffic lights, parking lots, and many other things are connected to each other in order to enable greater efficiency and provide a more comfortable lifestyle. Energy providers connect houses to buy or sell their own solar energy and provide additional digital services.
- Example: E.ON
- Smart retail and customer 360: Real-time integration between mobile apps of customers and backend services like CRMs, loyalty systems, geolocation, and weather information creates a context-specific customer view and allows for better cross-selling, promotions, and other customer-facing services.
- Example: Target
- Intelligent manufacturing: Industrial companies integrate machines and robots to optimize their business processes and reduce costs, such as scrapping parts early or predictive maintenance to replace machine parts before they break. Digital services and subscriptions are provided to customers instead of just selling them products.
Machine learning plays a huge role in many of these use cases, regardless of the industry, and you can read Using Apache Kafka to Drive Cutting-Edge Machine Learning for more insights.
Let’s now take a look at the 10,000-foot view of a robust IoT integration architecture.
End-to-end enterprise integration architecture
IoT integration architectures need to integrate the edge (devices, machines, cars, etc.) with the datacenter (on premises, cloud, and hybrid) to be able to process IoT data.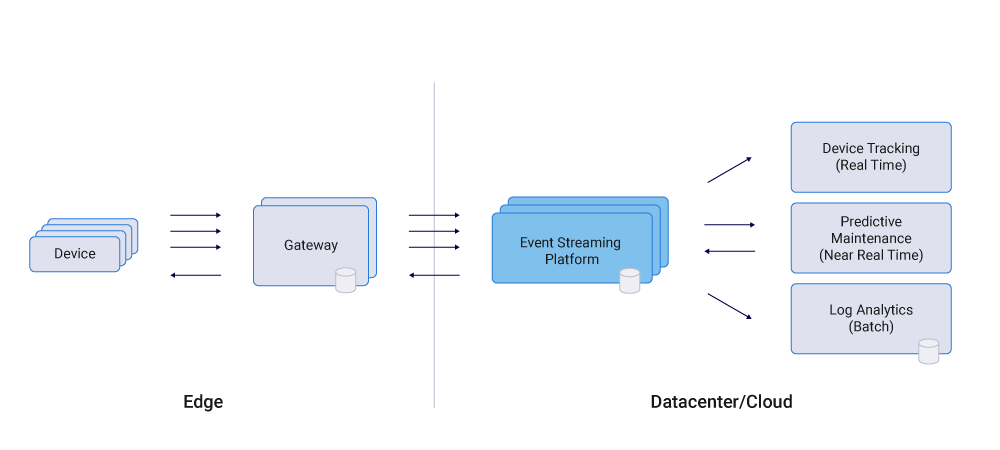
Requirements and challenges of IoT integration architectures
To be flexible and future ready, an IoT integration architecture should possess the following requirements:
- Scalable data movement and processing: handles backpressure and can process increasing throughput
- Agile development and loose coupling: different sources and sinks should be their own decoupled domains. Different teams can develop, maintain, and change integration to devices and machines without being dependent on other sources or the sink systems that process and analyze the data. Microservices, Apache Kafka, and Domain-Driven Design (DDD) covers this in more detail.
- Innovative development: new and different technologies and concepts can be used depending on the flexibility and requirements of a specific use case. For instance, one application might already send data to an MQTT broker so that you can consume from there while another project does not use an MQTT broker at all, and you just want to push the data into the event streaming platform directly for further processing.
But several challenges increase the complexity of IoT integration architectures:
- Complex infrastructure and operations that often cannot be changed—despite the need to integrate with existing machines, you are unable g to add code to the machine itself easily
- Integration with many different technologies like MQTT or OPC Unified Architecture (OPC UA) while also adhering to legacy and proprietary standards
- Unstable communication due to bad IoT networks, resulting in high cost and investment in the edge
Given these requirements and challenges, let’s take a look now at how MQTT and other IoT standards help integrate datacenters and the edge.
IoT standards and technologies: MQTT, OPC UA, Siemens S7, and PROFINET
There are many IoT standards and technologies available on the market. If we had to choose, these are the most common options for implementing IoT integrations:
- Proprietary interfaces: especially in Industrial IoT (IIoT), this is the most common scenario. Machines provide a large number of usually closed and incompatible protocols in a proprietary format. Examples are S7, PROFINET, Modbus, or an automated dispatch system (ADS). Supervisory control and data acquisition (SCADA) is often used to control and monitor these systems.
- OPC UA: this is an open and cross-platform, machine-to-machine communication protocol for industrial automation. Every device must be retrofitted with the ability to speak a new protocol and use a common client to speak with these devices. License costs and modification of the existing hardware are required to enable OPC UA.
- PLC4X: As an Apache framework, it provides a unified API by implementing drivers (similar to JDBC for relational databases) for communicating with most industrial controllers in the protocols they natively understand. No license costs or hardware modifications are required.
- MQTT: This is built on top of TCP/IP for constrained devices and unreliable networks, applying to many (open source) broker implementations and many client libraries. It contains IoT-specific features for bad network/connectivity, and is widely used (mostly in IoT, but also in web and mobile apps via MQTT over WebSockets).
No wonder technical know-how is not evenly distributed in both realms. In the IoT environment, for example, a large number of protocols for data exchange have developed in recent years. Only MQTT will seem familiar to an automation technology employee.
In the same way, industrial protocols are a book with seven seals for software engineers. It may be that some industrial protocols are well suited for a specific IoT solution, just as certain security features of modern IoT protocols are suited for industry. But that doesn’t move much.
MQTT has become the standard solution for most IoT scenarios today, especially outside of IIoT. Although MQTT is the focus of this blog post, in a future article I will cover MQTT integration with IIoT and its proprietary protocols, like Siemens S7, Modbus, and ADS, through leveraging PLC4X and its Kafka integration. For more details about using Kafka Connect and PLC4X for IIoT integration scenarios, you can check out these slides on flexible and scalable integration in the automation industry and the accompanying video explaining the relation between IIoT, Apache Kafka, and PLC4X.
Based on my conversations with industrial customers—who are pained by the challenges of closed, inflexible interfaces—I noticed that more and more IIoT devices and machines also provide an MQTT interface that can be integrated into modern systems.
Regarding the tradeoffs of MQTT, consider the pros and cons:
Pros
- Widely adopted
- Lightweight
- Has a simple API
- Built for poor connectivity and high latency scenarios
- Supports many client connections (tens of thousands per MQTT server)
Cons
- Just queuing, not stream processing
- Inability to handle usage surges (no buffering)
- Most MQTT brokers don’t support high scalability
- Asynchronous processing (often offline for long time)
- Lacking a good integration with the rest of the enterprise
- Single infrastructure (typically somewhere at the edge)
- Inability to reprocess of events
These tradeoffs show that MQTT is built for IoT scenarios but requires help when it comes to integrating into the enterprise architecture of a company. This is where the event streaming platform Apache Kafka and its ecosystem come into play.
Apache Kafka as an event streaming platform
Apache Kafka is an event streaming platform that combines messaging, storage, and processing of data to build highly scalable, reliable, secure, and real-time infrastructure. Those who use Kafka often use Kafka Connect as well to enable integration with any source or sink. Kafka Streams is also useful, because it allows continuous stream processing. From an IoT perspective, Kafka presents the following tradeoffs:
Pros
- Stream processing, not just queuing
- High throughput
- Large scale
- High availability
- Long-term storage and buffering
- Reprocessing of events
- Good integration with the rest of the enterprise
- Hybrid, multi-cloud, and global deployments
Cons
- Not built for tens of thousands of connections
- Requires a stable network and solid infrastructure
- Lacks IoT-specific features like Keep Alive and Last Will and Testament
Since Kafka was not built for IoT communication at the edge, the combination of Apache Kafka and MQTT together are a match made in heaven for building scalable, reliable, and secure IoT infrastructures.
How do you integrate both?
The following sections demonstrate three Kafka-native options, meaning you generally do not need an additional technology besides MQTT devices/gateways/brokers and Confluent Platform to integrate and process IoT data.
Confluent MQTT connectors (source and sink)
Kafka Connect is a framework included in Apache Kafka that integrates Kafka with other systems. Its purpose is to make it easy to add new systems to scalable and secure event streaming pipelines while leveraging all the features of Apache Kafka, such as high throughput, scalability, and reliability. The easiest way to download and install new source and sink connectors is via Confluent Hub. You can find installation steps, documentation, and even the source code for connectors that are open source.
The Kafka Connect MQTT connector is a plugin for sending and receiving data from a MQTT broker.
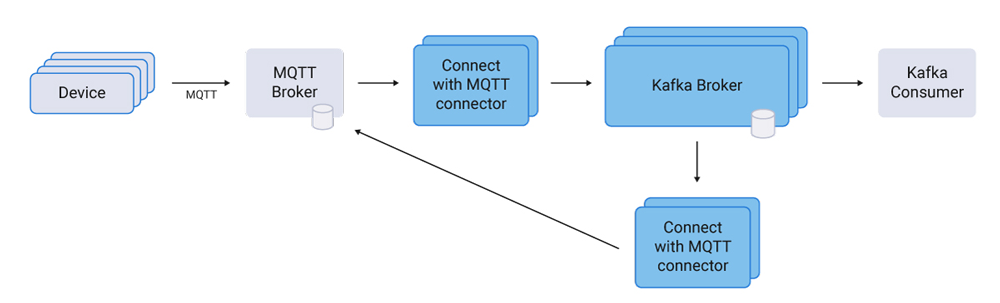
The MQTT broker is persistent and provides MQTT-specific features. It consumes push data from IoT devices, which Kafka Connect pulls at its own pace, without overwhelming the source or getting overwhelmed by the source. Out-of-the-box scalability and integration features like Kafka Connect Converters and Single Message Transforms (SMTs) are further advantages of using Kafka Connect connectors.
The MQTT connectors are independent of a specific MQTT broker implementation. I have seen several projects start with Mosquitto and then move towards a reliable, scalable broker like HiveMQ during the transition from a pilot project to pre-production.
MQTT Proxy for data ingestion without an MQTT broker
In some scenarios, the main challenge and requirement is to ingest data into Kafka for further processing and analytics in other backend systems. In this case, an MQTT broker is just added complexity, cost, and operational overhead.
Confluent MQTT Proxy delivers a Kafka-native MQTT proxy that allows organizations to eliminate the additional cost and lag of intermediate MQTT brokers. MQTT Proxy accesses, combines, and guarantees that IoT data flows into the business without adding additional layers of complexity.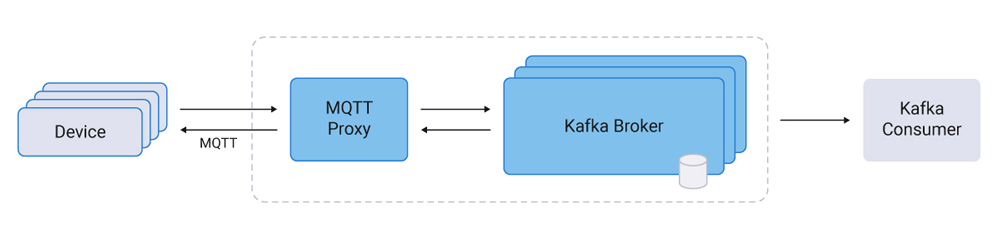
MQTT Proxy is horizontally scalable, consumes push data from IoT devices, and forwards it to Kafka brokers with low latency. No MQTT broker is required as an intermediary. The Kafka broker is the source of truth responsible for persistence, high availability, and reliability of the IoT data. Please note that producing from Kafka to IoT devices is not implemented yet at the time of writing this blog post.
However, although everybody thinks about IoT standards like MQTT or OPC UA when integrating IoT devices, oftentimes REST and HTTP(S) are a much simpler solution.
REST Proxy as a “simple” option for an IoT integration
REST Proxy provides a RESTful interface to a Kafka cluster, making it easy to produce and consume messages, view the state of the cluster, and perform administrative actions without using the native Kafka protocol or clients.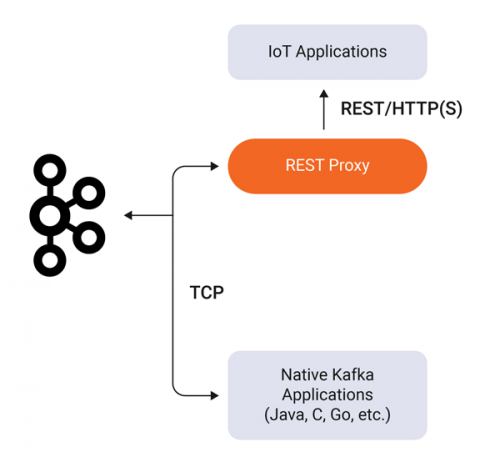
Why might you use HTTP(S) for an IoT integration? Due to various reasons, REST Proxy makes implementation and deployment simpler, faster, and easier compared with IoT-specific technologies:
- It’s simple and understood
- HTTP(S) Proxy is push based
- Security is easier from an organizational and governance perspective—ask your security team!
- Scalability with a standard load balancer, though it is still synchronous HTTP which is not ideal for high scalability
- Supports thousands of messages per second
No matter how you decide to integrate IoT devices, building a reliable end-to-end monitoring infrastructure is essential.
End-to-end monitoring and security
Distributed systems are hard to monitor and secure. A Kafka cluster is not much different—you have to monitor and secure the Kafka brokers, ZooKeeper nodes, client consumer groups (Java, Python, Go, REST, etc.), and Connect and ksqlDB clusters.
In terms of monitoring your whole Kafka infrastructure end to end, Confluent Control Center delivers insights into the inner workings of your Kafka clusters and the data that flows through them. Control Center gives the administrator monitoring and management capabilities through curated dashboards, so that they can deliver optimal performance and meet SLAs for their clusters. This includes:
- End-to-end monitoring from producers to brokers to consumers
- Management of Connect clusters (sources and sinks), no matter if it’s a central infrastructure or if there are domain-driven components in the architecture
- Role-Based Access Control (RBAC) for secure communication and ensuring compliance
- Monitoring and alerting for availability, latency, consumption, data loss, etc.
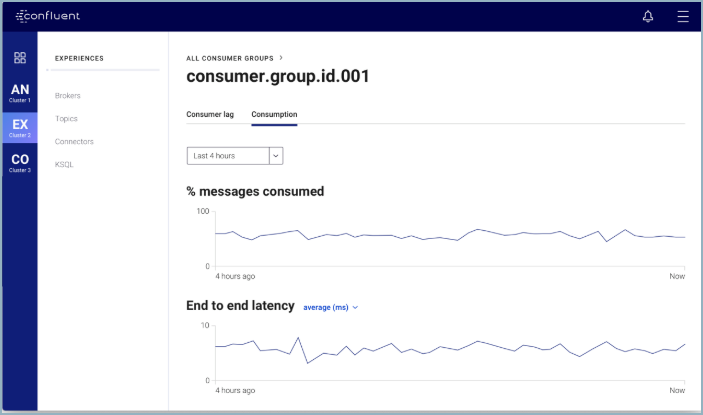
With security features like Role-Based Access Control (RBAC), you also have the ability to enable simple and standardized authentication and authorization for all components of the Confluent Platform.
Choosing the right components for your IoT integration challenges
The use cases for IoT integration scenarios are always similar: integrate with devices or machines; ingest the event streaming data in real time into the Kafka cluster (on premises or in the cloud); process the data with Kafka Streams and ksqlDB; and then send the data back to the device or machine, and/or to the other sinks like a database, analytics tool, or any other business application.
With Kafka-native options like clients, MQTT connectors, MQTT Proxy, or REST Proxy, you can integrate IoT technologies and interfaces to establish a powerful but simple architecture without using additional tools. This is especially recommended in 24/7 mission-critical deployments, where each additional component increases complexity, risk, and cost. You have many options, so choose the one that suits your situation best.
If you want to read a complete story about building an end-to-end IoT architecture from edge to cloud, read Enabling Connected Transformation with Apache Kafka and TensorFlow on Google Cloud Platform, which focuses on Google Cloud Platform, Confluent Cloud, and MQTT integration for building a scalable and reliable machine learning infrastructure.
The content of this blog post is also captured in this interactive lightboard recording called End-to-End Integration: IoT Edge to Confluent Cloud.
If you’re encountering similar challenges and use cases in your company, feel free to reach out and I’d be happy to discuss with you further.
Interested in more?
Download the Confluent Platform to get started with the leading distribution of Apache Kafka.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...