Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
The Definitive Guide to Building a Data Mesh with Event Streams
Data mesh. This oft-talked-about architecture has no shortage of blog posts, conference talks, podcasts, and discussions. One thing that you may have found lacking is a concrete guide on precisely how to get started building your own data mesh implementation. We have you covered. In this blog post, we’ll show you how to build a data mesh using event streams powered by Confluent Cloud, highlighting our design decisions, and the key benefits and challenges you’ll need to consider along the way. In fact, we’ll go one better: we’ve built a data mesh prototype for you to check out on your own to see what this would look like in action, or fork to bootstrap a data mesh for your own organization.
Data mesh is technology agnostic so there are a few different ways you can go about building one. The canonical approach is to build the mesh using event streaming technology that provides a secure, governed, real-time mechanism for moving data between different points in the mesh.
The prototype showcased in this blog takes the event streaming approach and as such is an opinionated implementation of the data mesh principles. Being a prototype, any approach you choose will need to vary based on your organization’s specific needs.
Want to dive straight in?
- Check out this video walkthrough of the prototype.
- You can run (and fork) your own copy of the prototype by following the steps outlined in the GitHub repo.
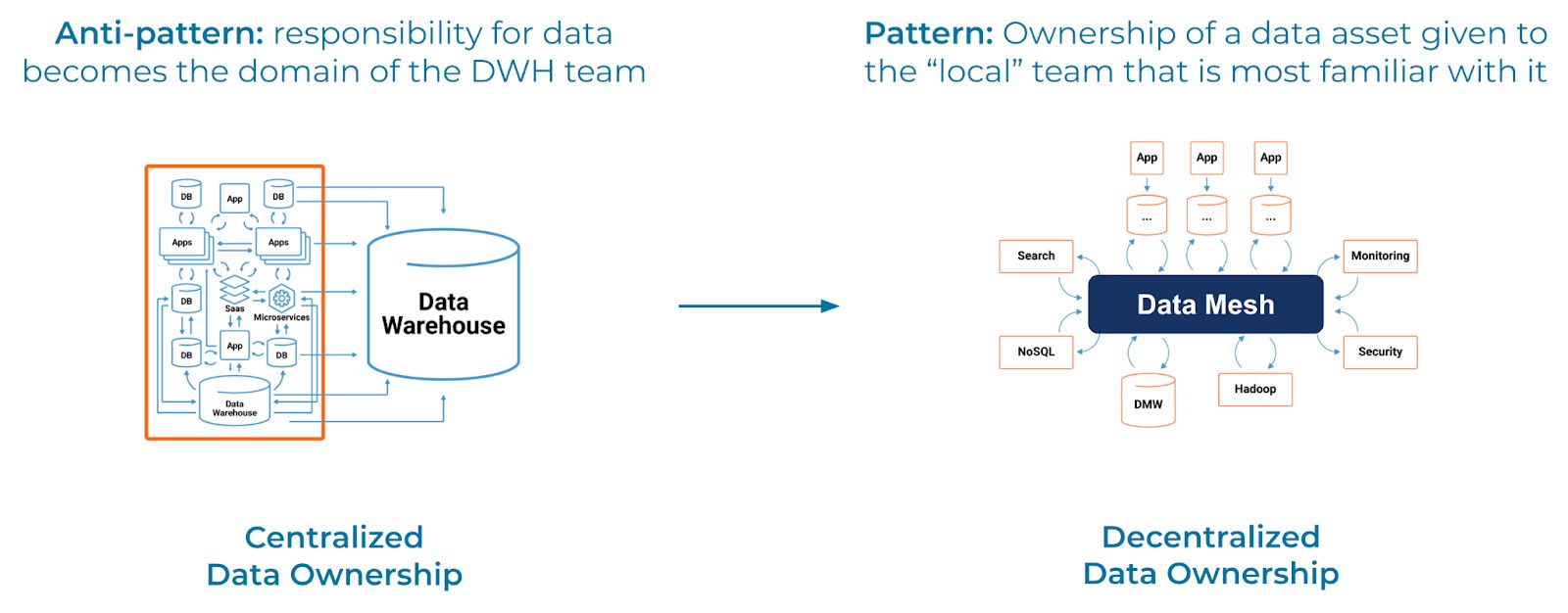
What is data mesh?
While data mesh sounds pretty cool, you may find yourself wondering “why do I want one?” The short answer is that traditional analytic architectures are often brittle, messy, and slow to change. The data mesh concept was introduced by Zhamak Dehghani to address these flaws by moving from a centralized to a decentralized approach. Traditionally, data is sourced from various systems, transformed, and loaded into a centralized data warehouse where it is analyzed by data analysts. This end-to-end process is often error-prone, brittle, and reactionary, in large part due to consistent, stable, and well-defined data not being available. This architecture places the responsibility for ensuring clean, available, and reliable data on the central data team, instead of on the team that owns, generates, uses, and stores it.
If you’ve worked in the analytics space you’ll likely be familiar with what happens next: frequent breakages, misinterpreted data, multiple (and often discordant) sources of truth pop up, and there becomes a pervasive lack of trust in the data analytics being generated. The goal of implementing a data mesh architecture is to fix these problems.
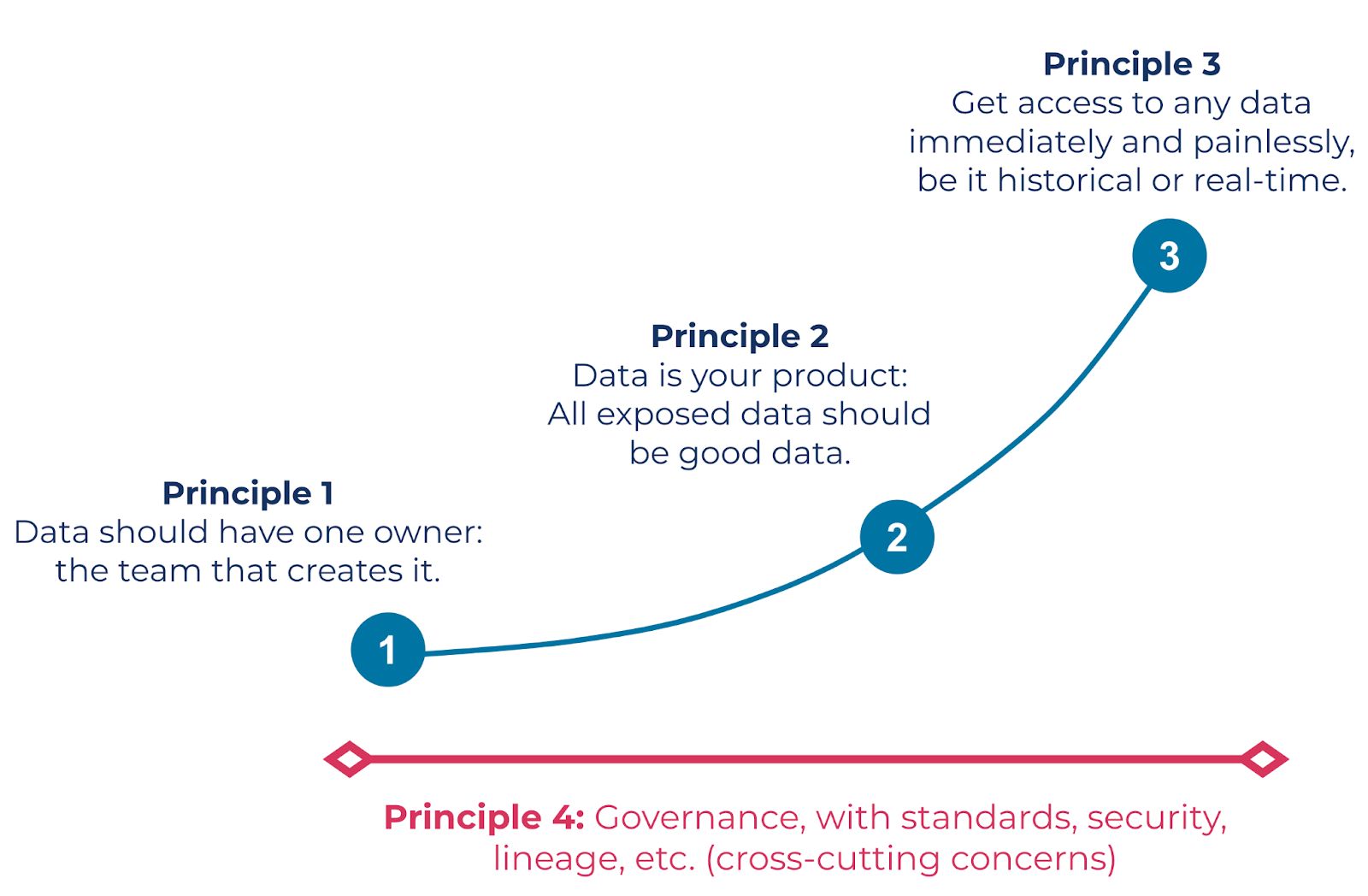
Zhamak categorizes the data mesh using four socio-technical principles: domain ownership, data as a product, federated computational governance, and self-service data platform. We’ll be touching on these four principles and how they relate to our implementation throughout this post. It’s encouraged you take a look at Zhamak Dehghani’s article Data Mesh Principles and Logical Architecture, as well as the Data Mesh 101 course on Confluent Developer. These sources serve as a foundation for the content in this blog post.

Source: John Martinez. (2010). How to Draw a Face.
Of course, principles are only the very start of implementing anything and data mesh is no exception. They create the guardrails that guide your implementation, much like basic shapes guide the process of drawing a person. Successful implementations will need principles to form a guide, practices to shape your technique, and tools that give your implementation its structure.
Why are event streams the best solution for a data mesh?
The fundamental building blocks of a data mesh are its data products. These are sources of well-formed data that are distributed around your company, each treated as first-class products in their own right. The idea is to carefully craft, curate, and present these to the rest of the organization as products for other teams to consume, providing a reliable and trustworthy source for sharing data across the organization. This counteracts the problem of bolted-on data feeds, added to systems as an afterthought and often forgotten about and left unmaintained until the inevitable incident.
In data in motion technologies, event streams are the primary building block and thus it shouldn’t be a surprise that event streams and data products are closely related. Our opinionated prototype makes event streams available in the mesh, including functionality for their discovery, consumption, creation, and management as data products. An event stream in the scope of this discussion is defined as an Apache Kafka® topic paired with a schema. We add metadata about the event stream to the data catalog when we publish it to the mesh, and together, the topic, schema, and metadata form the basic definition of a stream-based data product.
Benefits of event streaming for data mesh
There are several major factors that make event streams optimal for serving data products:
- Bridge the operational/analytical divide: Analytical and operational data is often served from different sources. For example, orders are created in an orders service and queried via a REST API, but the same orders are also available in a data warehouse for reporting. This can lead to hard-to-solve inconsistencies and divergent sources of truth, resulting in a loss of trust. Event streams enable all forms of operational, analytical, and hybrid workflows by providing a single data product source. For example, streaming use cases can consume directly from the event stream, while analytical use-cases can sink the data to a batch query system.
- Get data where it needs to be, in real time: Event streams are a scalable, reliable, and durable way of storing and communicating important business data. Streams are updated as new data becomes available, propagating the latest data to all consumers. Real-time data enables both streaming and batch use cases, including those that span different data centers, clouds or geographies.
- Consumers define their data models and storage: Consumers independently remodel the event streams, including mixing multiple data products together to come up with domain-specific use cases. For example, you might pull in customer and order data from the respective data products but then embellish that data with your own customer categorization scheme. This requires full control over all three datasets. This enriched data can be stored in a data store best suited for your query patterns, such as a key-value store for fast customer-based lookups.
Should a data product always be an event stream?
For this type of data mesh, the vast majority of data products can, and should, be served as event streams. They are extremely well suited to a vast range of data domains, given the incrementally updating nature, the ease of consumption, and the freedom to mix together streams of disparate data products. Event streams are the best option for serving your data products, particularly when that data is going to be used by multiple teams with unique needs across an organization.
However, some data products may be better served by other interfaces. For example, a data product relating to user locations may be best served by a geolocationing and search data store with a synchronous query API. Additionally, the data product may also not need to support any streaming functionality, such as a monthly financials aggregation that is only used to drive human-based inquiries.
For those of you who have specific non-streaming use cases, you can sink the event stream to the data store of your choice. Kafka Connect makes it easy to consume event streams, transform them, and write them to a wide range of endpoints. This makes it very easy to derive new materialized views of the data product, enabling you to use existing batch workflows and tooling.
That being said, our experience shows that the ever-increasing need to communicate data, at scale, across an organization, means that event streams will play an essential role in data mesh implementations.
The key to data mesh is people
Implementing a successful data mesh relies on several key social factors. By treating data as a product, you agree to apply to data the same rigor that we apply to other products, including controlled releases, versioning, addressing customer requirements, and providing a minimum service level agreement. If you do this, your customers get a consistent, reliable, and trustworthy way to access and consume your data for their business needs.
The data mesh is a federation of data products, sourced across the various domains of an organization, and used by other domains for their own business purposes. This is in contrast to previous data organization models, such as the data lake and data warehouse, where data is centralized into a single large grouping for common usage.
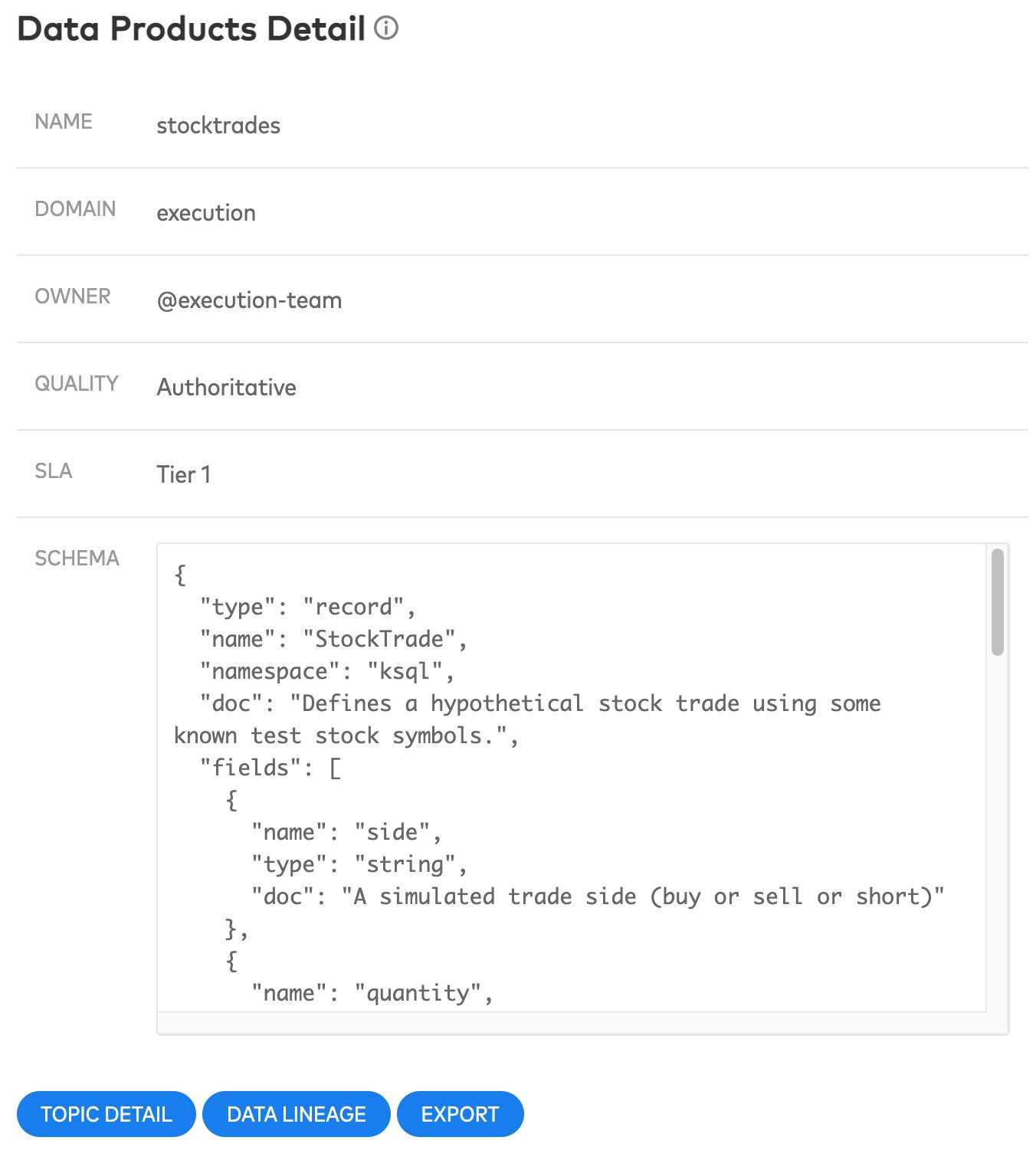
Data Product Details, as shown on Tab 1: “Explore Data Products”
One of the decisions we made for implementing our data mesh prototype is to require both domain and owner metadata for our published data products. This has several major advantages.
Domain and owner metadata provides you, a prospective consumer, with information about where their data is coming from. For example, the stocktrades data product has metadata denoting that it originates in the execution domain. The @execution-team is one of several teams in this domain. They take full ownership and responsibility for the stocktrades data product, including creating, publishing, and updating it. This, along with description, can help you to better understand the context of this product and decide if it’s the right one for you.
In a full-featured implementation, you would do well to link the owner to your own organization’s canonical list of teams (or people), such as one obtained from a list of GitHub teams or AWS IAM user groups. Further, clicking on the owner should open up a mechanism for communicating with them—either via an email address, or perhaps something more modern, such as opening an internal chat with your company’s instant messaging system.
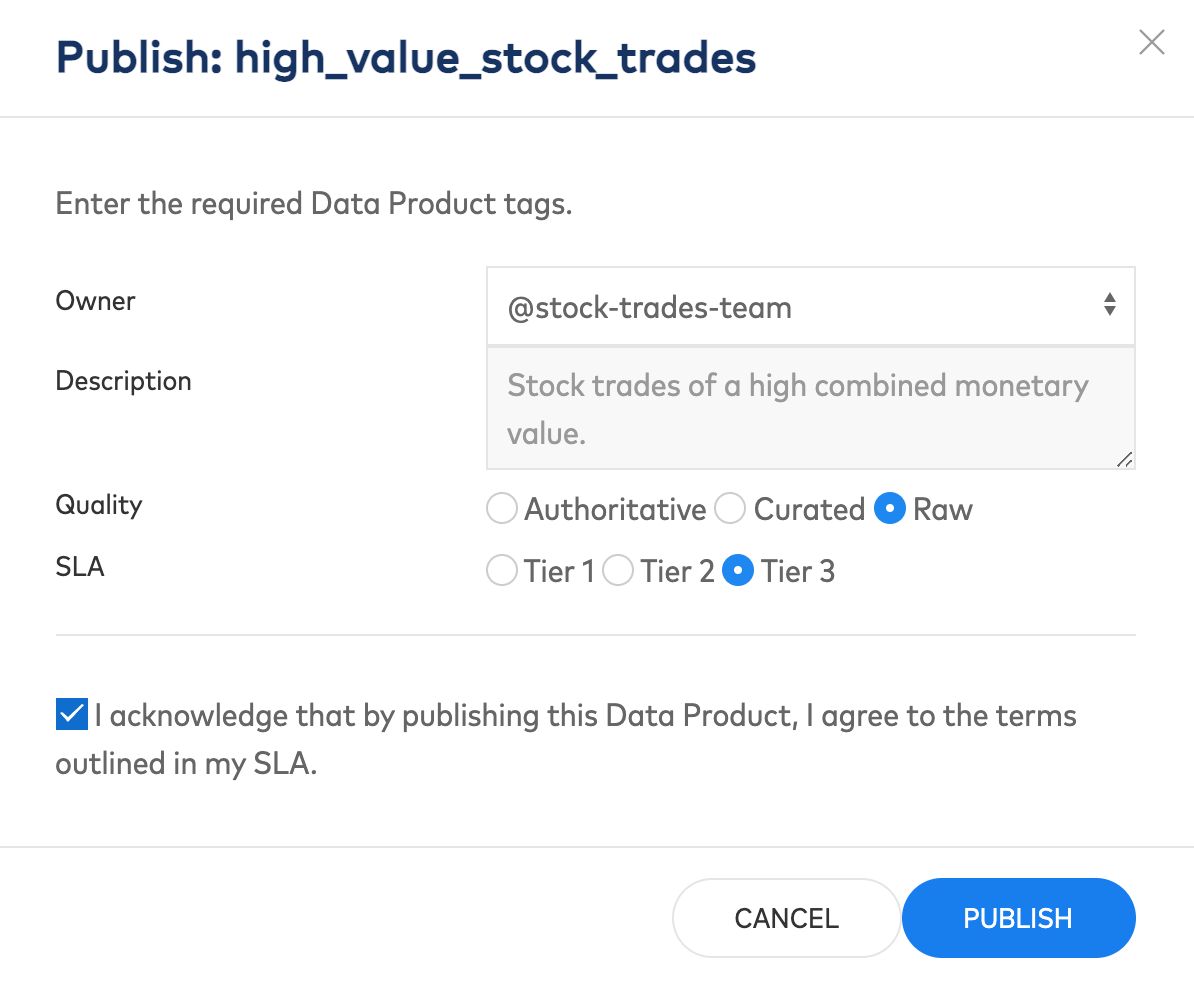
Each of these fields must be populated to publish an event stream as a data product, as part of federated governance requirements.
Data quality and Service Level Agreement (SLA) are the two other required metadata fields in our prototype. These help you identify the quality of a data set, differentiating canonical datasets (authoritative) from those with lower (curated) or no standards (raw). SLAs provided by the domain owner indicate the service level a consumer can expect when using the data product, helping prevent building mission-critical applications on insufficiently supported data products. These are two examples of metadata requirements that are set by the body of people charged with federated governance, the next pillar of data mesh.
Moving from centralized to decentralized necessitates data governance
Unlike centralized approaches like a data lake or data warehouse, a data mesh is federated–many sources and many sinks linked together as a mesh. As discussed, this comes with many benefits, teams can move faster with more autonomy over the data they consume. But the price paid for this freedom is a greater chance of divergence, which is a problem also seen in microservices architectures. Federated governance balances the inequality between freedom and divergence using a set of rules, regulations, and guidelines that do not restrict domain ownership, but facilitate cross-domain interoperability and make it easier to use data products.
The link between data mesh and microservices is no fluke: Federated governance in a microservice world deals with the balance between tight language and tooling conformity across the organization vs. an unstructured approach where developers can do whatever they wish. On one hand, you want your teams to be free to implement their microservices as best as possible. On the other hand, you want to reuse useful libraries and tooling and avoid an unnecessary sprawl of languages and technologies. The same is true here in the data mesh. Total conformity is an anti-pattern, but so is it being a free-for-all.
The data mesh governors must balance the needs of all participants and come up with the necessary compromises that make federation work. This group should establish such standards as:
- Data product types, which may include, for example, data products accessible via event streams, cloud storage services, gRPC APIs, REST APIs, or GraphQL queries.
- Schema types, such as enforcing Avro or Protobuf for all Kafka Topics while restricting JSON usage. Enforcing Parquet format in S3, while prohibiting the use of ORC.
- Product lifecycle guidelines, such as schema evolution requirements, handling breaking changes, and data product migrations, deprecations, and deletions.
- Security and access control standards, based on the best practices of the infosec team.
- Deprecation, deletion, and migration policies, such that data products can be gracefully decommissioned.
- Metadata, such as quality levels and SLAs, relating to well-defined organizational standards.
- Naming conventions, such as a domain name system to come up with consistent data product names, and to ease searching.
Enabling self-serve data products with the cloud
Minimizing the time from ideation to a working data-driven application is one of the key objectives of a good data mesh, and self-service is critical to accomplishing this goal. We have structured our prototype to showcase an end-to-end workflow of data product discovery, creation, and management—all features that make products as self-service as possible.
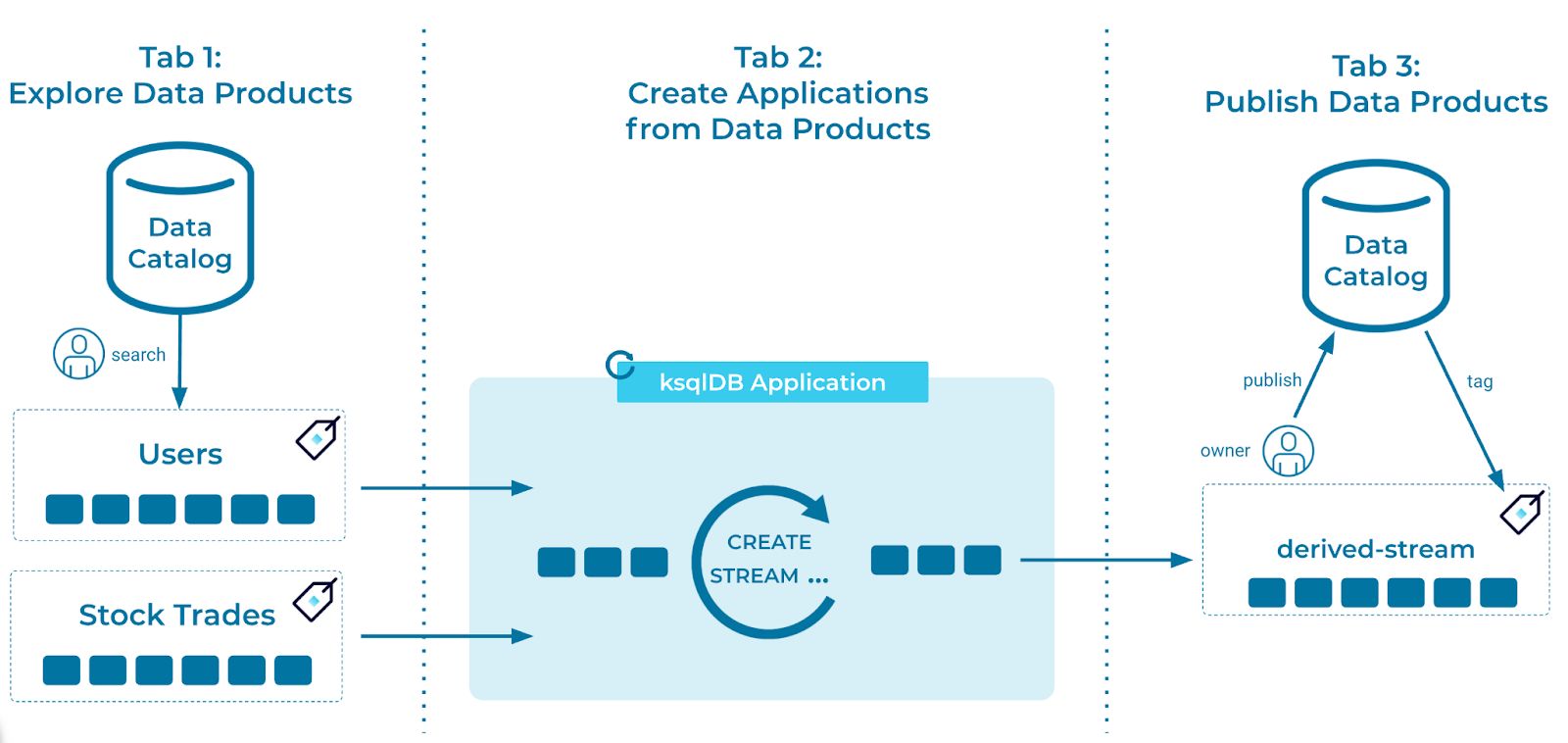
End-to-end workflow of data discovery, creation, and management
Data product discovery is just one aspect of self-serve. To effectively meet the needs of all consumers, data products must provide full access, on demand, to both current and historical data. By using event streams, consumers can autonomously select and read the historical data they need for their business use cases as many times as they require. This flexibility enables applications to build whatever data model and state they need to suit their business needs.
Cloud-native computing makes self service much easier. In our prototype, scaling concerns have been largely offloaded to Confluent Cloud. Compaction and Infinite Storage provide the means of serving the entire suite of historical events, letting you retain any amount of data as long as you need. You can start up a new consumer, read in the historical event stream data, and then continue processing in real time. This pattern of access is exemplified in the Kappa architecture and avoids the data inconsistency problems of reconciling batch and event stream sources of the Lambda architecture.
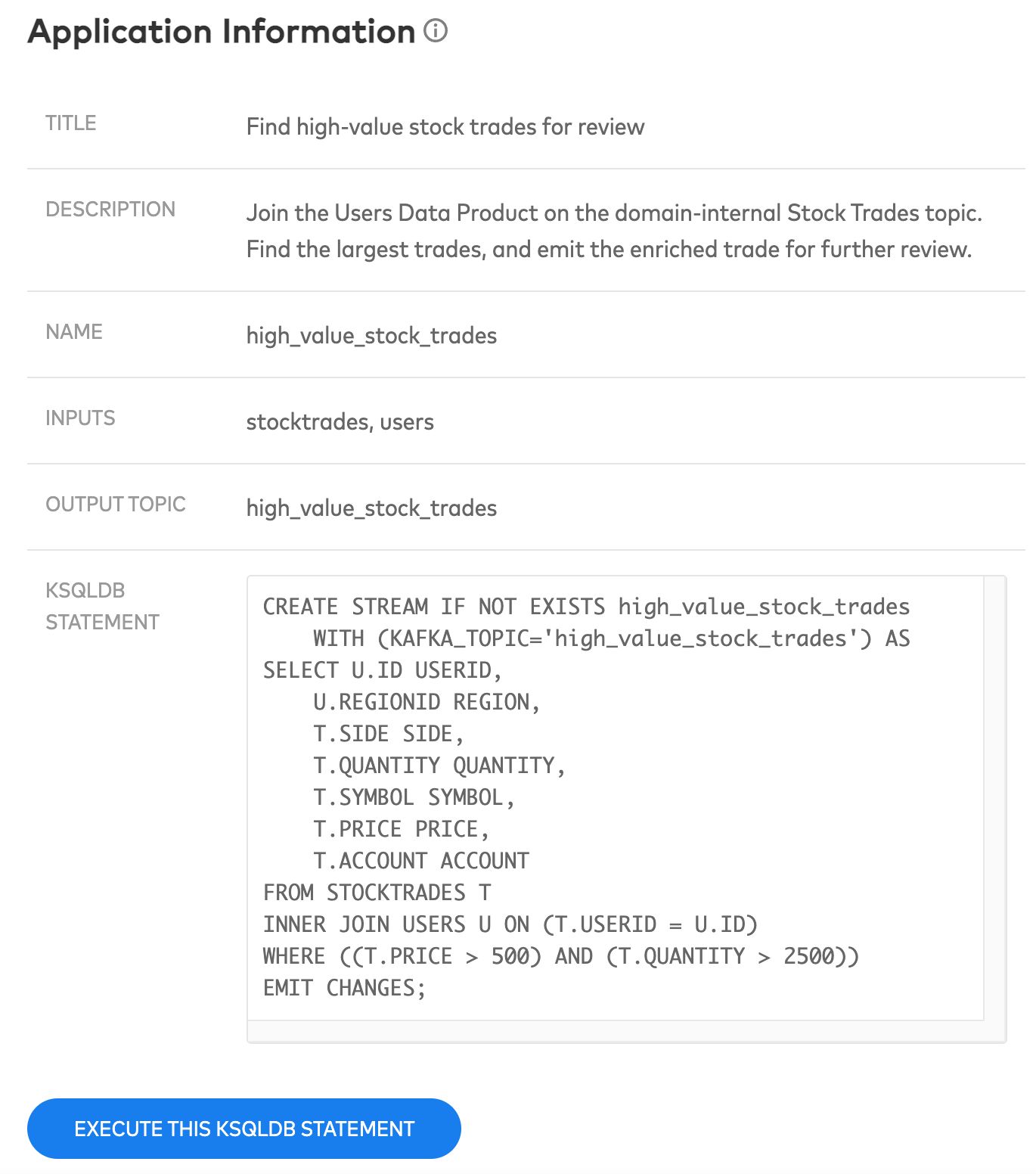
Sample ksqlDB business use case
Our prototype showcases several business use cases, complete with ksqlDB statements, to illustrate how easy it should be to access the data products. You could also achieve something similar by deploying an event-driven microservice, for example, that consumes from event streams and emits its own transformed events. In either case, the focus is to enable application developers to quickly build the applications they need for their domain while minimizing the overhead costs in accessing data.
Connecting legacy applications to a data mesh can also pose a challenge, as it may be infeasible for older systems to consume event streams. Kafka Connect simplifies these issues by providing the means to sink data products to a destination data store. You can also create data products powered by change-data capture connectors. For example, you can use the database write through pattern to create rich events with low latency, while avoiding expensive polling queries of production systems.
Once you publish a data product to the data mesh, you remain responsible for ensuring the minimum agreements of their product are met. A failure to meet these requirements should be treated like any other service outage. The emergency response may be limited in the case of low-tier data products and those with very accommodating SLAs, while a Tier 1 data product with a very tight SLA may require an on-call rotation to support.

Removing a data product from the mesh can be done at the click of a button. However, the data product owner needs to be certain that all consumers of the product have been notified and have migrated off. Though not included in this prototype, a useful extension of this prototype would be to deprecate the data product prior to deletion and notify existing consumers of the need to migrate. Meanwhile, access to new consumers could be prevented by rejecting new consumer read access requests on the topic.
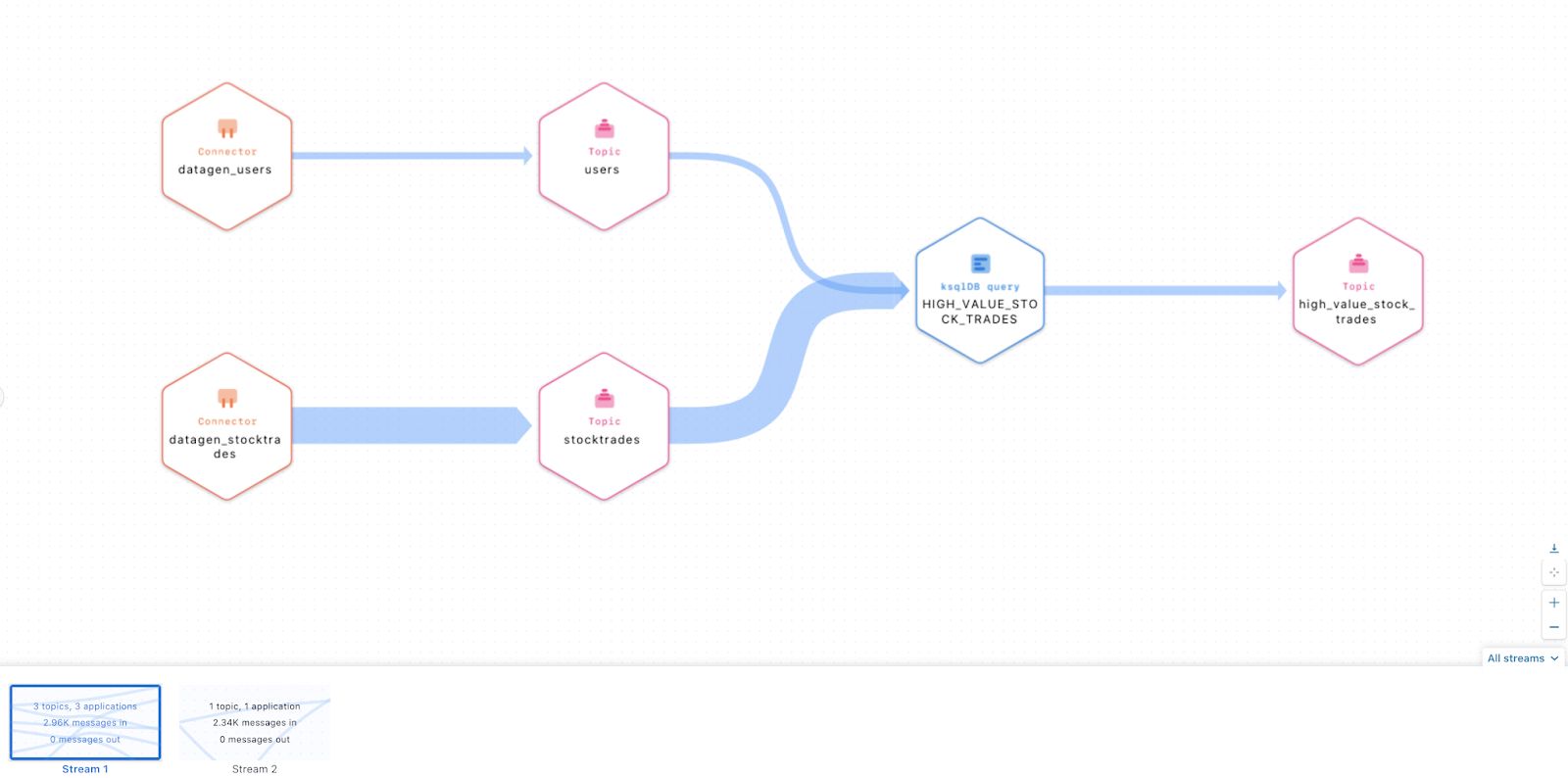
Stream Lineage helps you visualize and find dependencies
A good self-serve data mesh platform will track and account for all consumers and producers of the data products, and provide you with the lineage of the dependencies. Lineage helps identify data product consumers, so that they can be notified about upcoming deprecations, deletions, and breaking schema changes.
Try our data mesh prototype and learn how it works
This prototype is written in Spring Boot Java with an Elm frontend. It is backed by Confluent Cloud, including Apache Kafka, ksqlDB, the schema registry, and the recently released data catalog. You can run (and fork) your own copy of the prototype by following the steps outlined in the GitHub repo. The source code is freely available for you to use however you like.
If you deploy this prototype locally, it will create a cluster, several Kafka topics, a ksqlDB application, and some data generators to populate the topics. Schemas are registered to the schema registry as events are produced, while the data catalog stores the data product’s metadata.
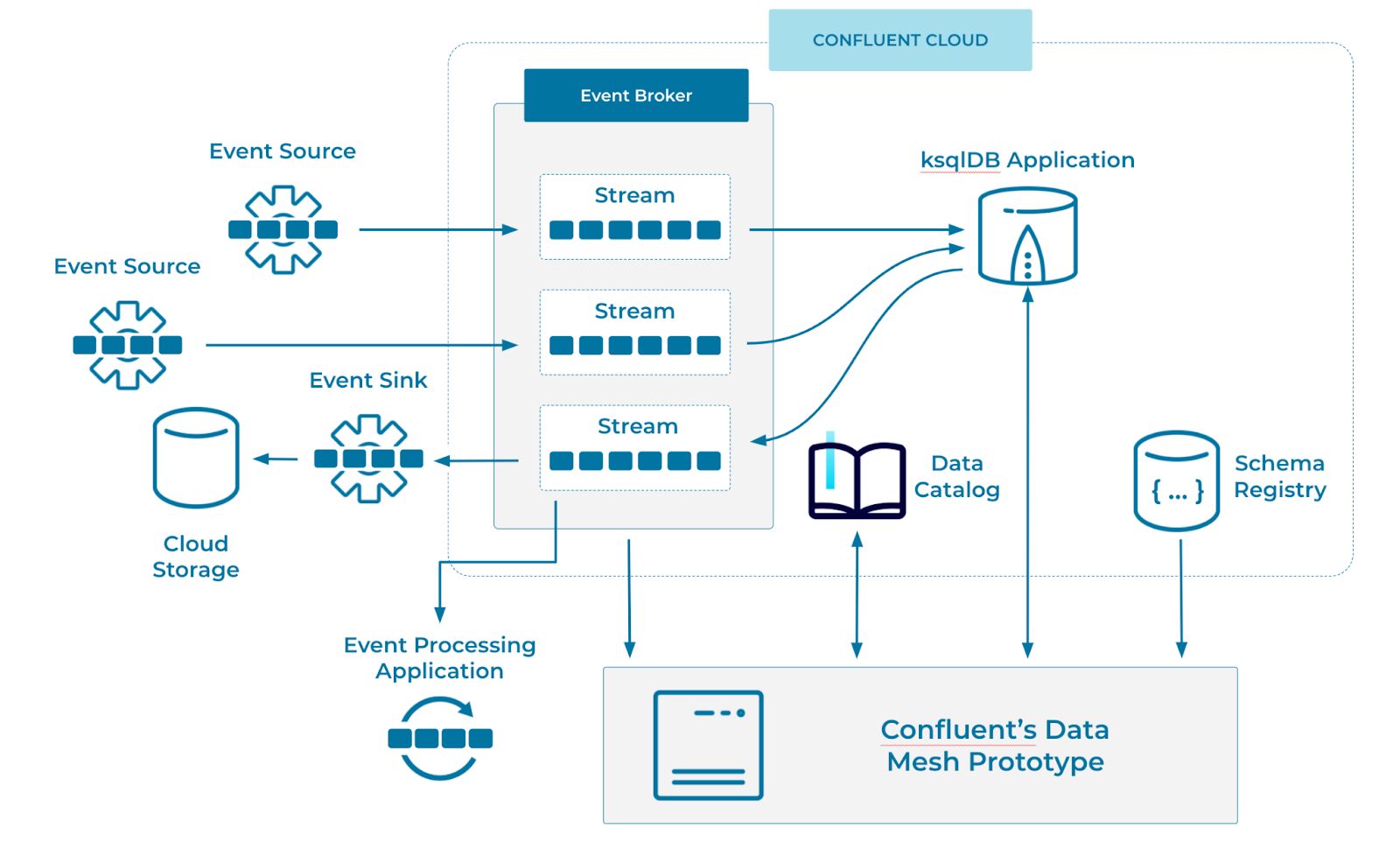
Our prototype interacts with Confluent Cloud via REST APIs. A data product’s metadata is stored in the data catalog and includes a reference to the associated topic and schema. This information is pulled into the prototype when viewing data products for discovery and publishing. The prototype also interacts with hosted ksqlDB via its REST API to create the sample business applications, kicking off a ksqlDB application with the long-running query.
Completing the data mesh
The idea of this post is to be a definitive guide, yet our prototype only takes you part of the way, So what do you need to build the ultimate data mesh? There are a few more pieces that need attention:
- Notifications: Integrate with an email or messaging system to notify people when a data product is created, updated, deprecated, or deleted.
- Automated regulatory validation: Validating data products against various data protection acts (such as GDPR), security compliance checks, and data locality policies that prevent data from leaving certain regions.
- Integrated sign-off process: Validate data products during code review, such that breaking changes cannot accidentally be deployed. Changes to the data product need to be validated by existing consumers and signed off before committing.
- Automatically handle incompatible data product changes: In the case that breaking changes are required, automatically creating a new data product, deprecating the old one, and notifying the existing consumers to migrate can reduce errors. You may also need to automate support of both the old and new data products until all consumers migrate to the new one.
- Additional event stream metadata: Event streams may contain only recent data (eg: last 30 days), a compacted snapshot of state, or all events ever published to the product. Exposing this information enables better self-service and tempers user expectations.
Conclusion
The data mesh is a federation of data products, sourced across the various domains of an organization, and used by other domains for their own business purposes. It is not centralized like a data warehouse or data lake.
Event streams are the best implementation medium for a data mesh. They provide highly scalable and efficient access to all consumers, letting each one choose how to use, process, store, and act on the data. They’re also incredibly successful at bridging the analytical/operational divide, giving a consistent view of data for both batch and streaming users while reducing data quality issues. The formalization of data access–meaning all teams use the same interface to the mesh–makes it easier to track where data is going and who is accessing it, promoting strong governance and lineage tracking across your domains.
Just as containers and container workload management systems like Kubernetes have transformed the way we build and deploy applications, event streams change the way we access data. By publishing event streams as well-defined and well-documented data products, you provide your business with the data building blocks needed to power event-driven microservices, content serving applications, analytical workflows, batch jobs, and many other services. A good data mesh will make it easy to access, use, and publish data products. Your time should be spent using the data and building applications, not struggling to find and interpret data, nor building your own access mechanisms.
This prototype shows how a data mesh can work in practice. We encourage you to go try out the prototype, fork it for your own needs, and join us in our community if you have any questions. Additionally, check out this podcast where I talk more about Data Mesh and data modeling!
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Streaming Data Integration with Apache Kafka®
Streaming data integration supports enriched, reusable, canonical streams that can be transformed, shared ,or replicated to different destinations, not just one.



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.