Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Designing the .NET API for Apache Kafka
Confluent’s clients for Apache Kafka® recently passed a major milestone—the release of version 1.0. This has been a long time in the making. Magnus Edenhill first started developing librdkafka about seven years ago, later joining Confluent in the very early days to help foster the community of Kafka users outside the Java ecosystem. Since then, the clients team has been on a mission to build a set of high-quality librdkafka bindings for different languages (initially Python, Go, and .NET) and bring them up to feature parity with the Java client.
Leading up to the 1.0 release, we’ve put a lot of effort into the .NET client in particular. This came about because there was a strong case for making a set of non-backwards compatible API changes to support various new features (e.g., the ability to produce custom timestamps) and to make the API more idiomatic (e.g., expose all errors via exceptions). We wanted to make all these changes at once rather than string them out over time to avoid continually inconveniencing users. The API we’ve arrived at was built with a lot of care and attention to detail, adds many features, and is very extensible.
So what’s new?
Strongly typed configuration classes
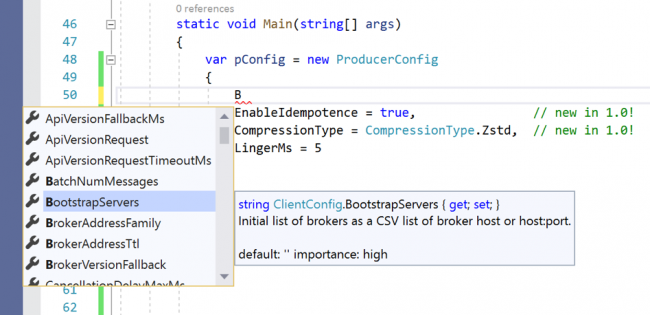
The first thing you’ll probably notice are the strongly typed configuration classes: ProducerConfig, ConsumerConfig, and AdminClientConfig. These classes are actually a layer on top of the untyped dictionary approach used in previous versions, though in most cases, there is no longer any reason to make use of that capability.
Strongly typed configuration classes are helpful because properties and their types are validated at compile time before you run your application. If you’re using an editor that supports code analysis, such as Visual Studio (Code), this validation happens at edit time as well and you can interactively see which configuration properties are available and their documentation via IntelliSense.
Here’s an example of configuring a producer in Visual Studio:
Builder pattern
Having specified your configuration settings, the next step in constructing a client is to pass this to a builder class. Builder classes are also new in v1.0 and were added to bring more flexibility to the client creation process.
One important requirement addressed by the builder classes is that of specifying event handlers. In the v0.11.6 API, event handlers are specified by subscribing to C# events (e.g., OnLog). This happens after client creation, which is a problem because clients may emit events before the application has had a chance to register a corresponding handler. It would have been possible to address this by caching events for some time after client startup, but that approach is messy and less accurately models the problem domain.
In addition to event handlers, serializers and deserializers (collectively known as SerDes) are also set via the builder classes. This allows for two new features added in version 1.0 to be catered for simultaneously—default SerDes for common types and support for more than one type of SerDe (async and sync). This combination of requirements is not well accommodated by the constraints of a simple constructor argument list, which is how SerDes were previously specified.
Here’s an example of how you might create a consumer using the new API:
using (var consumer = new ConsumerBuilder<Ignore, string>(config) .SetValueDeserializer(customStringSerializerImpl) .SetStatisticsHandler((_, json) => Console.WriteLine($"Stats: {json}")) .SetPartitionsAssignedHandler((c, partitions) => { // called on consumer group rebalance immediately before // the consumer starts reading from the partitions. You // can override the start offsets, and even the set of // partitions to consume from by (optionally) returning // a list from this method. }) .Build()) { ... }
In addition to the builder classes that are constructed using a config settings object, there are builder classes which allow you to create producers and admin clients by passing the value of an existing client’s Handle property to their constructor. Clients created in this way reuse the broker connections of the existing client. In the case of the producer, data is also combined in protocol-level broker requests where possible, which leads to a considerable increase in efficiency.
For more information on how to configure and use the Consumer, Producer, and AdminClient check out the examples in the .NET client GitHub repo.
Serialization
Designing a serialization API that’s flexible enough to allow for advanced use cases, such as integration with Confluent Schema Registry, posed a number of challenges.
First of all, if we allow for schema validation/registration to happen as a side effect of (de)serialize operations, they will sometimes need to wait on network IO. In previous versions of the library, SerDes simply blocked on the async HTTP operations (a practice known as sync over async). From the point of view of thread utilization, there is little downside to doing this because schema validation is required very infrequently, as schemas are cached on the client. But sync over async in .NET comes with a number of gotchas, and it’s best practice to avoid it altogether. For this reason, in the v1.0 API, we provide async friendly (de)serialization interfaces.
On the flip side of this requirement, we care a lot about performance. Kafka is known for its high throughput, and it’s one of the reasons people choose Kafka over other technologies. Unfortunately, the overhead of using Tasks—although not too high—is measurable, so we don’t want SerDes to pay the associated price unless required. For this reason, we provide sync SerDe interfaces in addition to the async ones and allow either to be specified via the builder classes.
The second challenge posed by Schema Registry integration is that SerDes care about their context. If part of the responsibility of the serializer is to perform schema compatibility checks, then the SerDes need more information than just the data being (de)serialized. This is because schemas are generally registered against specific subjects (a combination of topic and key/value suffix), and the SerDe needs to know this information. Thus, we bundle these two pieces of contextual information together in a SerializationContext class and pass this to the (de)serialize interface methods.
Ease of use is what matters most
It’s tempting to look at the structural complexity that arises from the requirements of Schema Registry aware SerDes and wonder if we might have been better off choosing a more decoupled approach.
We actually considered a number of other options. The most basic and flexible of these would be for the clients to only work with unserialized data, requiring that the user explicitly apply (de)serialization before/after their produce/consume calls. Another approach might be to integrate only “simple” serializers into the core clients and provide separate abstractions for the more complex Schema Registry enabled case.
These options would indeed have resulted in simpler, more focused abstractions, but there is a tradeoff—the additional flexibility makes the abstractions more difficult to use. Making the SerDes the integration point for Schema Registry effectively shifts complexity away from the user and into the library implementation. The design is more constrained, but this is actually beneficial because it (a) results in an API that is simpler to use and (b) prevents it from being used incorrectly.
Message class
The v1.0 API introduces a new general purpose Message class that encapsulates the contents of a message (key, value, timestamp, and headers). This class doesn’t include any information about where a message was published—it relates only to the “what,” not the “where.” This is a very foundational concept in Kafka, making the class widely useful.
One place it’s used is in the producer API. For example:
var deliveryResult = producer.ProduceAsync( topicName, new Message<int, string> { Key = key, Value = val });
Notice how C#’s object initializer syntax allows message components to be selectively specified inline? By comparison, in the v0.11.6 API, message components are specified as function arguments. The big problem with this approach is it doesn’t scale well as more parameters are added because of the need for different method overloads to support different usage scenarios, and in v1.0, we added support for two more message components: timestamp and headers.
An additional place the Message class is used is in the DeliveryReport and DeliveryResult classes to expose the message used in the corresponding produce call. It’s also used by the ConsumeResult class to provide the actual contents of the consumed message. Finally, you’ll find this class a useful building block when creating higher level abstractions on top of the basic clients.
There’s more!
In this post, we’ve covered some of the higher-level API changes we’ve made to the .NET client in the v1.0 release. But this is just the start—we’ve taken the opportunity to reconsider almost every aspect of the API and have made many other improvements, including:
- Better/more idiomatic error reporting and exception class hierarchy
- Addition of the IProducer, IConsumer, and IAdminClient interfaces, enabling the clients to be mocked to facilitate testing
- Changes that allow for more streamlined consume loop logic
The Confluent .NET client is now one of the more polished APIs for Kafka. Moving forward, you can expect to see some of the concepts in this client show up in Confluent clients for other languages.
One final note—if you’re passionate about designing great APIs, there’s plenty more of this to be done at Confluent. We’re hiring across the board, including on the clients team.
Getting started
To get started, check out the Apache Kafka for .NET Developer course on Confluent Developer. Or spin up a cluster on Confluent Cloud and give the new .NET client a try.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...