Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
The Easiest Way to Install Apache Kafka and Confluent Platform – Using Ansible
With Confluent Platform 5.3, we are actively embracing the rising DevOps movement by introducing CP-Ansible, our very own open source Ansible playbooks for deployment of Apache Kafka® and the Confluent Platform.
Why Ansible?
Since its release seven years ago, Ansible has become the most popular automation tool for configuration management.
Unlike other configuration management tools, it allows for a much simpler deployment model due to its agentless nature. By using passwordless SSH, it’s able to communicate with all of Confluent Platform’s supported operating systems in a clean, frictionless way.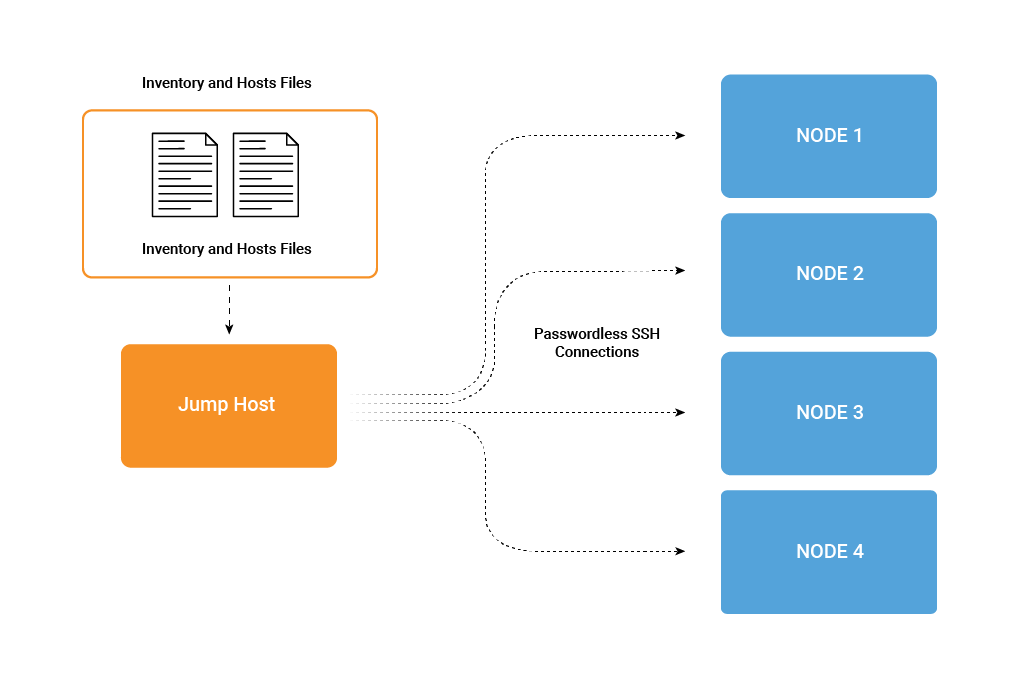 Ansible uses YAML, which has a clean and simple syntax that serves as an easy starting point while also being incredibly flexible. It allows the state of the infrastructure to be described in a very readable way using files that have a logical structure.
Ansible uses YAML, which has a clean and simple syntax that serves as an easy starting point while also being incredibly flexible. It allows the state of the infrastructure to be described in a very readable way using files that have a logical structure.
For example:
all:
vars:
ansible_connection: ssh
ansible_user: ec2-user
ansible_become: true
sasl_protocol: plain
As an open source project written in Python, Ansible is constantly being improved by its community, and new modules are being added regularly. This leads to even greater stability and flexibility as the community continues to grow.
What can you do with CP-Ansible?
With the 5.3 release of CP-Ansible, we’ve added many capabilities to our playbooks to help simplify setup and configuration of the Confluent Platform while utilizing best practices.
To get started, first read the hosts you have defined in your inventory file and make sure that the correct hostnames are specified in each component’s configuration in order to define the correct communication paths. This includes making sure that the brokers have the right hostnames to communicate with each other, as well as with Apache ZooKeeper™, Confluent Schema Registry, and any additional components in the cluster. This allows you to scale across N hosts and to know that you always have the correct configuration.
We then apply our best practices to both the host and the Confluent Platform component. For example:
- Set up service accounts for each component and only allow those service accounts to access the specific configurations and data for the given component
- Set open file limits for each service installed to ensure that enough file descriptors are available
- Configure the Log4j rolling file appender for each component installed to consolidate logging to a centralized location while limiting the amount of logging generated
You can also customize your installation by overriding key variables within the playbook. In the case of overriding the ID on a broker, you would modify the hosts_example.yml as follows:
ip-172-31-34-246.us-east-2.compute.internal:
broker_id:
For a more complete list of variables that you can override, review the confluent.variables role for global variables. For component-specific variables, you can review confluent./defaults/main.yml. Both are located in the roles directory. You can override any of these variables via your hosts_example.yml, similar to the broker_id example above.
In addition to the above best practices and ability to customize, CP-Ansible greatly simplifies security deployment through:
- TLS—both one way and mutual
- Kerberos with TLS
- SCRAM with TLS
- SASL PLAIN with TLS
CP-Ansible playbooks allow you to specify which security protocol you wish to deploy with. By having the prerequisites for the given security protocol in place, the playbooks will deploy across any given number of components/hosts specified.
Using CP-Ansible to deploy a cluster with SASL PLAIN security
In this tutorial, we will deploy a cluster with SASL PLAIN security using CP-Ansible. The minimum installation requirements can be found in the documentation.
1. Clone the CP-Ansible repository to the host you wish to deploy from:
git clone git@github.com:confluentinc/cp-ansible.git
2. Copy hosts_example.yml to hosts.yml:
cp hosts_example.yml hosts.yml
3. Edit hosts.yml using the editor of your choice. In this instance, we are using vi:
vi hosts.yml
4. Set the ansible-user: property to be a user who has sudo access on the hosts you wish to deploy to:
all:
vars:
ansible_connection: ssh
ansible_user:
ansible_become: true
5. Uncomment this variable to enable sasl_plain and make sure it aligns with the all group:
# sasl_protocol: plain
6. Under each component name, modify the hosts: section to reflect the hostnames or IP addresses of the hosts you wish to deploy to:
zookeeper: hosts: Ip-10-0-0-34.eu-west-2.compute.internal:
7. Save your edits to the hosts.yml file.
8. Execute the following command:
ansible-playbook --private-key= -i hosts.yml all.yml
9. You will now see the playbooks execute:
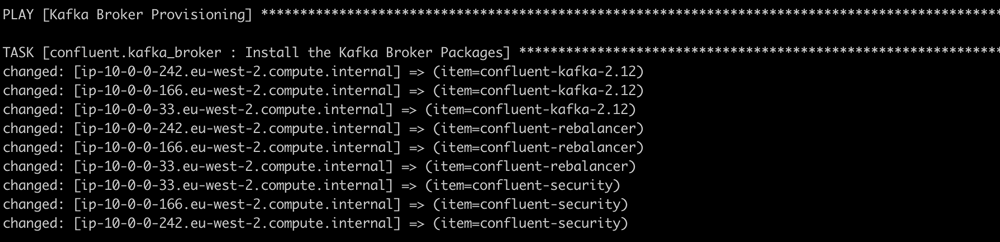
10. When completed successfully, you should see output similar to the following:

Validating your installation
To validate your installation, access the Confluent Control Center interface by opening your web browser and navigate to the host and port where Control Center is running. Control Center runs at http://localhost:9021/ by default.
When you first open Control Center, the homepage for your clusters appears. The homepage provides a global overview of all clusters managed by the Control Center instance. Each cluster tile displays its running status, Kafka overview statistics, and connected services.
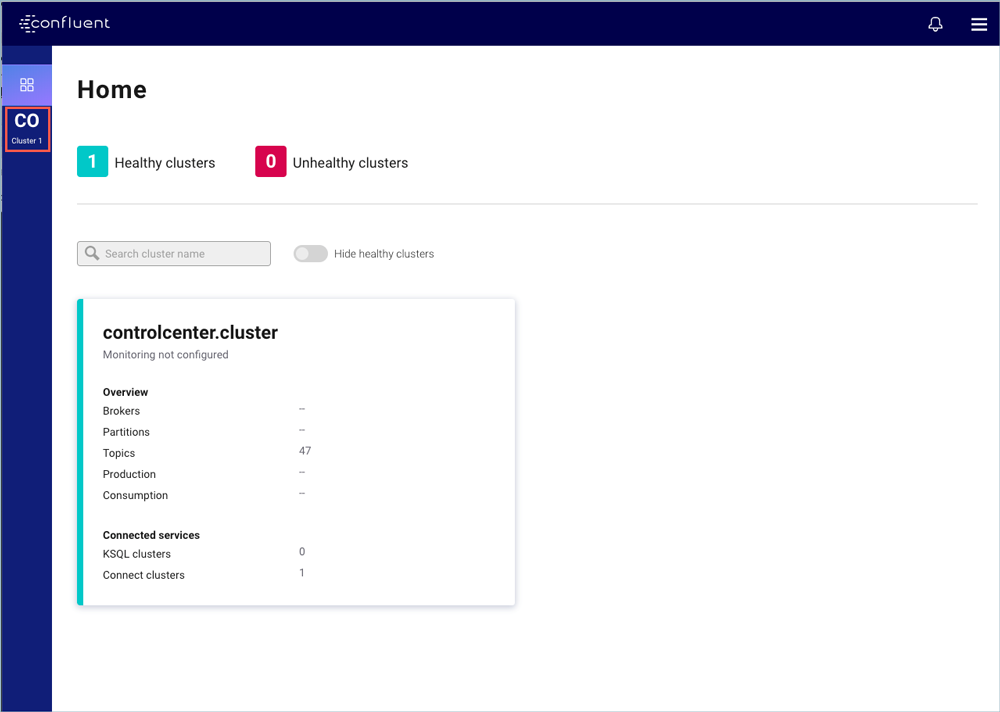
You should see something similar to the image above showing one healthy cluster and a list of components. You can drill into individual clusters by clicking on the cluster name for more details.
How to contribute to CP-Ansible
We highly value your contributions as CP-Ansible should reflect the needs of the Apache Kafka and Confluent communities. These include code contributions, but just as importantly, feature requests and bug reports.
You can contribute code, bug reports, and feature requests to the public repository by using the contributions guide.
If you have a commercial support contract with Confluent, feel free to open a support case with our world-class support team.
What’s next for CP-Ansible?
We have many exciting new capabilities coming to CP-Ansible in the short and medium terms, including but not limited to:
- Rolling upgrades
- RBAC configuration
- Support for FIPS operational readiness
- A best practices guide for using CP-Ansible in a multi-staged environment
Until then, I encourage you to learn more by listening to this episode of the Streaming Audio podcast.
And, if you haven’t already, you can download the Confluent Platform and easily spin up an installation using the playbooks and templates from CP-Ansible.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.