Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
From Apache Kafka to Amazon S3: Exactly Once
At Confluent, we see many of our customers are on AWS, and we’ve noticed that Amazon S3 plays a particularly significant role in AWS-based architectures. Unless a use case actively requires a specific database, companies use S3 for storage and process the data with Amazon Elastic MapReduce (EMR) or Amazon Athena. But even if a use case requires a specific database such as Amazon Redshift, data will still land to S3 first and only then load to Redshift.
Landing data to S3 is ubiquitous and key to almost every AWS architecture. This explains why users have been looking for a reliable way to stream their data from Apache Kafka® to S3 since Kafka Connect became available.
So, it happened. In March 2017, we released the Kafka Connect S3 connector as part of the Confluent Platform. In just the first month, our users stored over 200 TB of data to S3 using the connector. With multiple companies moving to production since then, we estimate the S3 connector has uploaded over 75 PB of data to date.
In what follows, I’ll describe what makes this connector both easy to use and highly reliable. I’ll begin by explaining why we had to write a new connector and will show you how easy it is to use. Finally, I’ll close with a deeper dive into the design, explaining how we implemented an exactly once connector on top of S3’s eventual consistent storage.
Why another S3 connector?
When customers were asking for an S3 connector, there were already several Kafka-to-S3 solutions out there at the time, so we had to decide whether to adopt an existing S3 connector, modify the Kafka Connect HDFS connector (as some developers attempted to do) or write a new connector from scratch.
We knew that our users needed three things from the connector:
- Integration with the Kafka Connect API: Connect’s scaling and fault tolerance capabilities were important to have, and users didn’t want yet another system that they’d need to learn how to use, deploy and monitor.
- Exactly once: Users didn’t want to waste expensive compute cycles on deduplicating their data. And no one likes missing events.
- No extra dependencies: Especially dependencies on additional datastores. Kafka clients and the S3 SDK libraries should be all you need to get events from Kafka to S3. Simplicity rules, especially in a distributed systems world where simple is often the key to being reliable.
When we considered the existing connectors, we noticed that none of them delivered the reliability and exactly once capabilities we wanted. They treat S3 like it’s another filesystem—though it isn’t really. For example, S3 lacks file appends, it is eventually consistent, and listing a bucket is often a very slow operation.
Reusing an existing connector didn’t meet the needs users were looking for. This led us to design the Kafka Connect S3 connector and rethink our key abstractions from scratch. The result was a connector that is fast, depends only on Kafka to restore state and is easily configured to export data without duplicates. How about we take it for a spin?
Try it yourself!
For this demo, I’ll use one of my favorite public feeds: real-time reservations in Meetup groups around the world. What I like about this stream of events is that, although it is described in a simple JSON format, it contains rich information such as location, user interests and timestamps with every record. Given that events are produced in real time and at a reasonable pace, the Meetup feed is pretty handy for demos with real data.
The S3 connector has been available since Confluent Platform 3.2.0. To export the data to S3, I’ll need to set up credentials to my S3 account and create an S3 bucket with the right permissions.
Step 1: Start all the services—ZooKeeper, Kafka and the Connect worker
Begin by starting ZooKeeper, Kafka and Connect:
confluent local start connect
Note: The syntax shown is for Confluent Platform 5.3 or newer. If you haven’t installed the Confluent CLI yet, you can read the installation instructions.
Step 2: Start ingesting feed data to Kafka
Create a Kafka topic with five partitions to a single Kafka broker running locally:
bin/kafka-topics --zookeeper localhost:2181 --create --topic meetups --replication-factor 1 --partitions 5
Then, to ingest the events from the public Meetup feed, use a simple piped command that combines curl and the Confluent CLI.
curl -s http://stream.meetup.com/2/rsvps | confluent local produce meetups
I can confirm that data is actually written to Kafka as follows:
confluent local consume meetups -- --from-beginning
Step 3: Set up credentials and create the S3 bucket
On the cloud side, first create an S3 bucket with the appropriate permissions. For instance, here I’ve created a bucket that is private and accessible by me, the user that will run the S3 connector. After setting permissions, I just need to pick a name and a region for my S3 bucket.
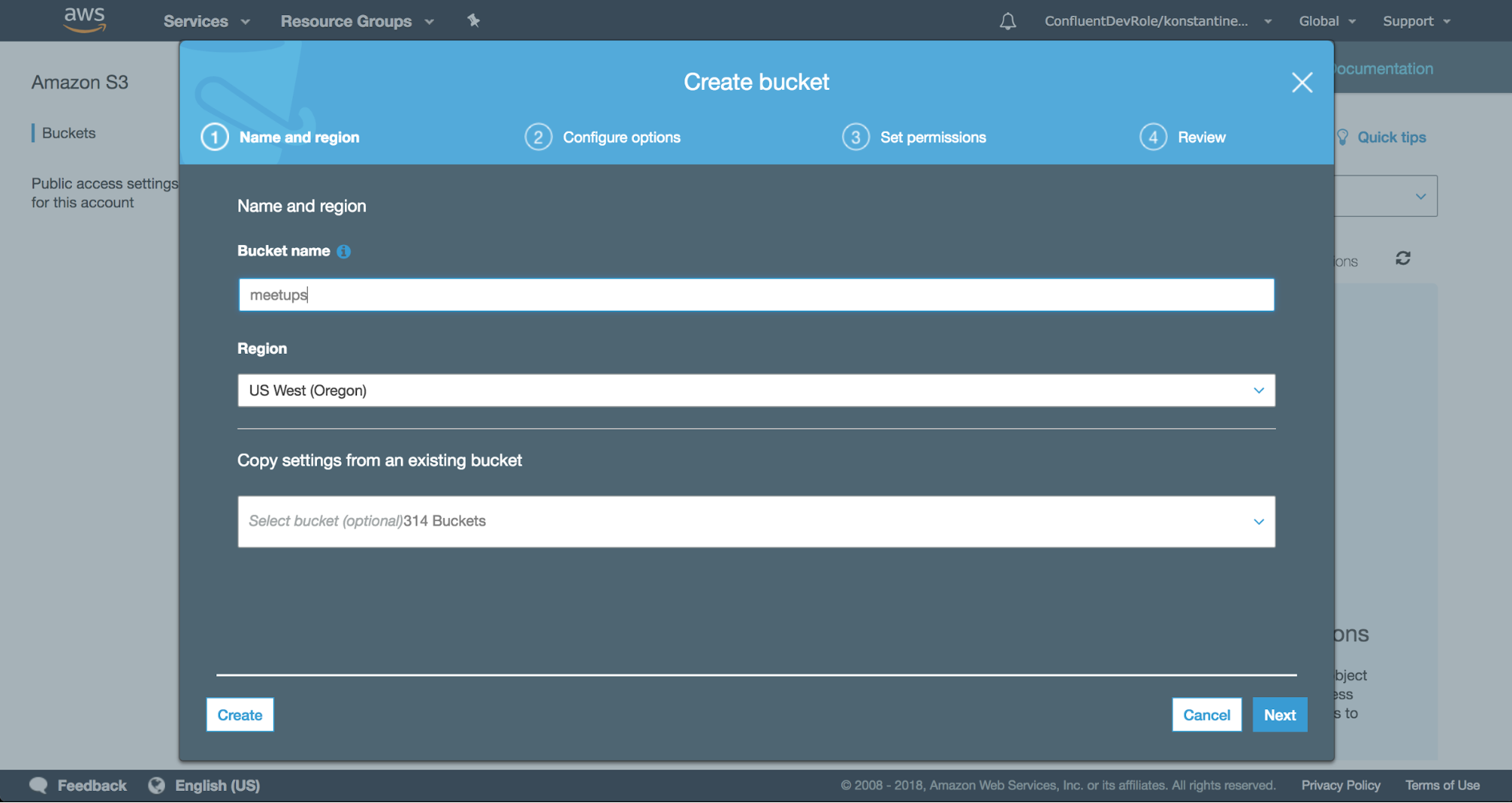
For the S3 connector to authenticate successfully when it contacts S3, I need to setup my AWS credentials. An easy way to do that, is to export two environment variables:
export AWS_ACCESS_KEY_ID=foo export AWS_SECRET_ACCESS_KEY=bar
Make sure you replace foo and bar with your actual AWS credentials. Using environment variables to pass credentials to the connector is not the only way to authenticate. Under the covers, the S3 connector uses the default credentials provider included with the AWS SDK (DefaultAWSCredentialsProviderChain), and this makes several mainstream options for authenticating available to users.
For those who need to customize authentication even further, the S3 connector accepts a provider class as a configuration property that, in turn, can be configured with additional properties with the s3.credentials.provider. prefix. For a complete list of options, read more in the S3 connector documentation.
Step 4: Configure and start the S3 sink connector
Configure the S3 connector by inserting its properties in JSON format, and store them in a file called meetups-to-s3.json:
The S3 connector can partition records in S3 in several ways. With the above properties, I have chosen to run the S3 connector using time-based partitioning and therefore group Kafka records in objects to S3 according to a timestamp. The timestamps I use here are timestamps of the Kafka records themselves but you can also specify a field in the payload itself as the timestamp value to use.
Grouping records in S3 objects by their Kafka timestamps is convenient, because the timestamps of Kafka records are ordered and monotonically increasing within a partition in Kafka. The fact that I rotate an object every minute (rotate.interval.ms) means that every new file that appears in S3 will contain records that were published in Kafka within a single minute.
Now that I’m only one REST API call away from starting the S3 connector, I’ll issue the call using the Confluent CLI:
confluent local load meetups-to-s3 -- -d ./meetups-to-s3.json
The equivalent command using curl directly would be:
curl -X POST -d @meetups-to-s3.json http://localhost:8083/connectors | jq
By inspecting the logs of the Connect worker, I’ve confirmed that the connector has started correctly:
INFO Starting connectors and tasks using config offset 9 INFO Starting connector meetups-to-s3 INFO Starting task meetups-to-s3-0 INFO Creating task meetups-to-s3-0
Soon after, still at the INFO log level, you’ll see that the S3 connector first catches up with the messages that have been published already in Kafka and then uploads an object approximately every minute, according to the timestamps of the Kafka records:
INFO Files committed to S3. Target commit offset for meetups-0 is 12478
INFO Files committed to S3. Target commit offset for meetups-0 is 12613
INFO Files committed to S3. Target commit offset for meetups-0 is 12759
INFO Cluster ID: s5EbMmZQRdaDh-vARJ_WpQ
INFO Files committed to S3. Target commit offset for meetups-0 is 12863
INFO WorkerSinkTask{id=meetups-to-s3-0} Committing offsets asynchronously using sequence number 1: {meetups-0=OffsetAndMetadata{offset=12863, metadata=''}}
INFO Files committed to S3. Target commit offset for meetups-0 is 13035
INFO WorkerSinkTask{id=meetups-to-s3-0} Committing offsets asynchronously using sequence number 2: {meetups-0=OffsetAndMetadata{offset=13035, metadata=''}}
INFO Files committed to S3. Target commit offset for meetups-0 is 13205
INFO WorkerSinkTask{id=meetups-to-s3-0} Committing offsets asynchronously using sequence number 3: {meetups-0=OffsetAndMetadata{offset=13205, metadata=''}}
INFO Files committed to S3. Target commit offset for meetups-0 is 13339
INFO Cluster ID: s5EbMmZQRdaDh-vARJ_WpQ
INFO WorkerSinkTask{id=meetups-to-s3-0} Committing offsets asynchronously using sequence number 4: {meetups-0=OffsetAndMetadata{offset=13339, metadata=''}}
The view on the AWS S3 console also confirms the real-time upload of Meetup events from Kafka to objects in S3, with an object being created approximately every minute, as intended by our configuration.
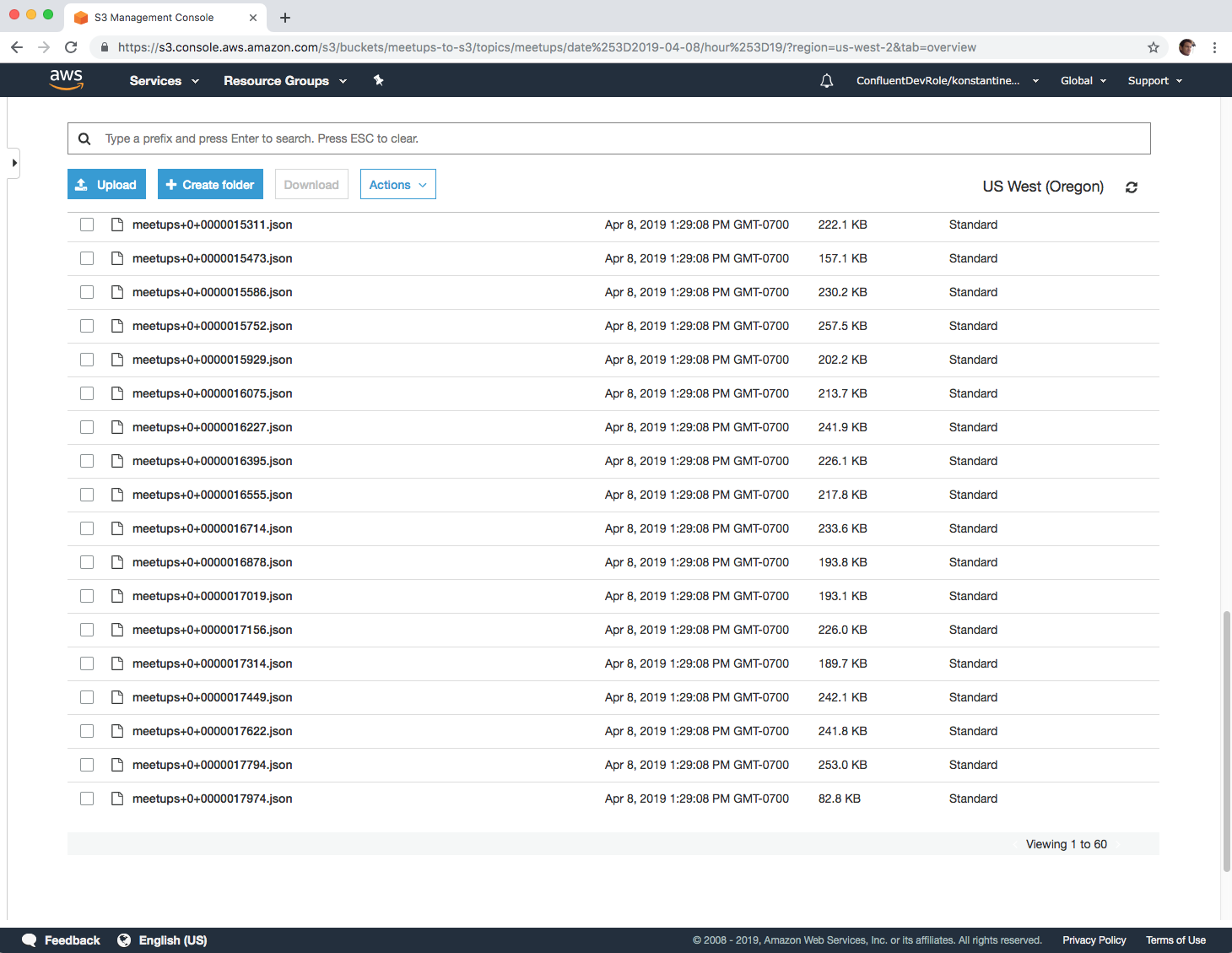
But how is this possible on top of an eventually consistent object store? Read on to see how we approached the challenge of avoiding duplicates in the S3 connector.
How we implemented exactly once streaming on eventually consistent S3
If you play around a bit with the pipeline we defined above, for example by restarting the S3 connector a few times, you will notice a couple of things: No duplicates appear in your bucket, data upload continues from where it was left off, and no data is missed. How is this accomplished under the covers?
In order to provide the S3 connector with exactly once semantics, we relied on two simple techniques:
- S3 multipart uploads: This feature enables us to stream changes gradually in parts and in the end make the complete object available in S3 with one atomic operation.
- We utilize the fact that Kafka and Kafka partitions are immutable. Therefore, if we upload the same range of offset twice, we get the exact same file.
Starting with S3, the key feature of its SDK that allows this connector to deliver data without duplicates is multipart uploads. In S3, every upload is atomic. An object is either present as a whole in S3 or not present at all. However, for a streaming data platform to upload data in a streaming fashion, the ability to perform the uploads incrementally is key for a connector.
Using multipart uploads, the S3 connector uploads each file gradually in parts, but this process is transparent to the users. They only see the end result, which is the complete file. This fact makes the S3 connector a robust exactly once connector since, even under the presence of failures, the apps that read files from S3 will always read the same files and contents once they become available as complete objects in S3.
Furthermore, in the presence of failures or in between restarts, the connector is able to pick up data export where it left off. In a few cases, this might mean that it will have to re-upload parts of an upload that were not completed. Again, this does not affect downstream applications reading records from S3 since such applications see the whole file, which is always the same if the partitioner that is used distributes Kafka records the same way every time.
The value of Kafka is that it makes exactly once semantics efficient and robust. Because of S3’s eventual consistency, we don’t probe S3 to recover state. At the same time, we also refrain from using the local disk of Connect workers to track the connector’s progress. Kafka is treated as the sole source of truth. This fact simplifies recovery from faults significantly. The connector just needs to commit offsets to Kafka once an upload is successful. On every restart, the connector worker starts to export records immediately from where it left off.
By not persisting the data to local disks, the connector is able to run faster, while Kafka is responsible for resilience and Connect workers are used to scale up data export in a stateless fashion.
Here are three examples that highlight how exactly once semantics are preserved in different situations:
- The S3 connector uploads a set of records to S3 using a partitioner that rolls a new file every 90 records. Let’s assume that each record takes 1 MB and the connector is configured to upload parts of 25 MB each. Let’s also assume that the connector starts consuming records from Kafka at offset 180. After the connector uploads the three parts of size 25 MB each successfully, the last part, with the remaining 15 MB is uploaded and the connector completes the multipart upload. S3 assembles the parts into a single file. This is a very quick operation in S3. Finally, the S3 connector commits the offset of the last Kafka record that was uploaded successfully when this multipart upload completed. The next starting Kafka record offset will be 270.
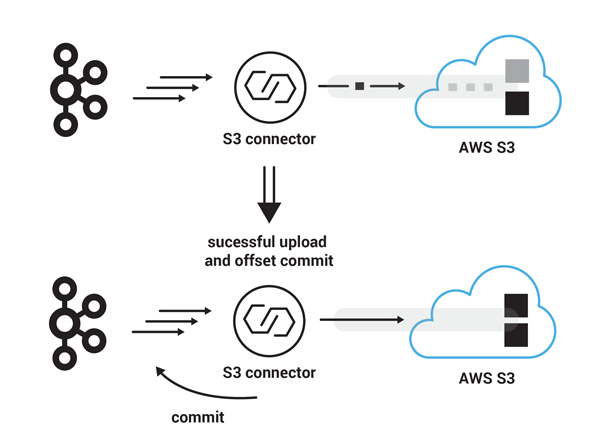
Successful upload and offset commit
- In a similar scenario, the S3 connector starts uploading another set of 90 records to S3, with starting offset 270. However, this time, somewhere in between uploading part three and part four, the Connect cluster experiences a hard failure, bringing the S3 connector offline for a short period of time. Even though this failure has interrupted the S3 connector from uploading the next 90 records in a single file, the users on the S3 side will not notice such a failure in the form of partial data because the file has not become visible yet. Once the S3 connector is back online, it will resume execution from the latest committed Kafka record offset, which is still 270 and after the multipart upload of all four parts succeeds this time, it will make available the new set of 90 records as a new file on S3. The next Kafka offset to be consumed will be 360.
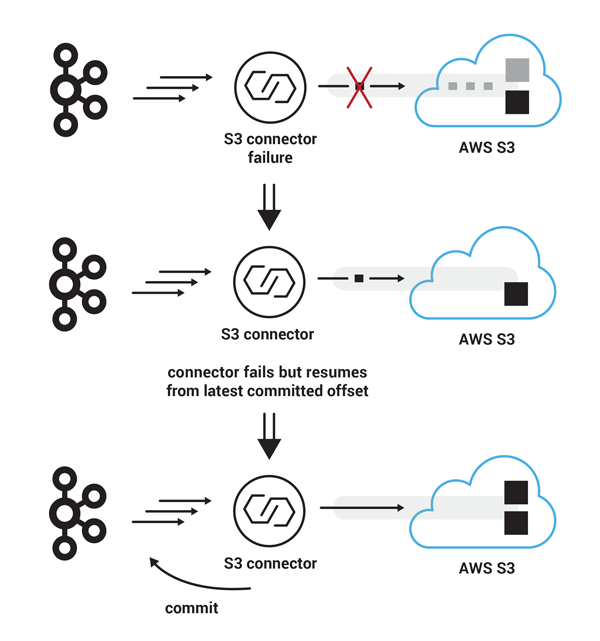
Failure during multipart upload and restart from latest committed offset
- In a different failure scenario, the S3 connector successfully uploads another set of 90 records to S3, with starting Kafka record offset 360, in four parts. The multipart upload completes successfully on the S3 side. However, this time, the commit message that attempts to store the record offset back to Kafka is lost. In this case, the S3 connector will resume from its latest saved Kafka offset, which is again 360. In the meantime the file that was previously uploaded to S3 is available to S3 users. In this scenario, the S3 connector avoids duplicates, because when the second attempt to upload the same 90 succeeds, the previous file will be overwritten in an atomic operation by the new file with the same name. This time offset commit succeeds on the Kafka side and the S3 connector is ready to consume new records from offset 450.
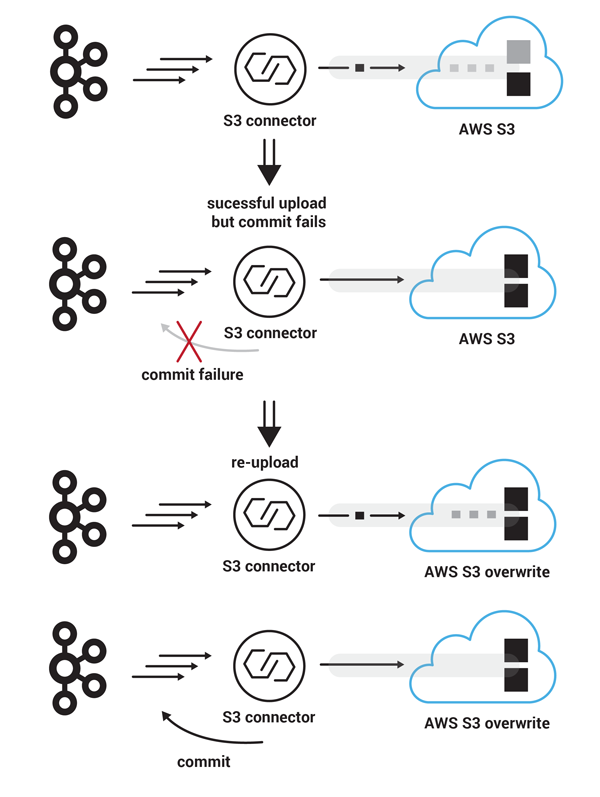
Failure during offset commit and restart from latest committed offset
Conclusion
Since its initial release, the Kafka Connect S3 connector has been used to upload more than 75 PB of data from Kafka to S3. If you haven’t used it yet, give it a try by following the quick start or the demo as described. If you are one of the many users already using the S3 connector in production and development environments and you wish a missing feature was present, feel free to let us know by contributing an issue or a pull request to the S3 connector’s GitHub repo.
If you’d like to know more, you can download the Confluent Platform and get started with the leading distribution of Apache Kafka.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...